分布式系统下的日志收集分析方案
前言
分布式系统下,大规模集群应用分布在数台甚至成百上千台不同的服务器上,而日志又是我们开发人员用于定位问题、监控系统健康度、用于报警的最基础的数据来源。要想快速方便的对日志进行查找、分析归纳、归档、报警等功能,使用传统的 Linux 命令去查看日志,肯定不现实。所以一般的分布式集群系统环境下,我们都会去构建一个集中的日志系统,可以将各个服务日志收集起来。从而达到我们需要的的效果。
业务规模复杂导致构建分布式日志系统的难点:
- 导致的日志多节点、日志量也在爆炸式的增长;
- 日志格式的不规范与不确定性;
- 日志的形式的复杂化(物理机/虚拟机、K8S、Docker,Application 等等),容器的标准输出,容器内文件、容器事件、K8S事件等等;
- 环境复杂、在K8S环境下的,机器宕机、上下线、POD销毁、扩容缩容引起的日志的更改,都需要瞬时的收集起来;
- 日志的种类多(Nginx 、CDN、Ingress、ServiceMesh Pod等等日志,审计日志、应用日志、中间件日志、调用链日志、网络日志等等)
- ……
日志的特点:
- 大量的数据, 流式数据;
- 上述的步骤,应该要解耦
- 要具体扩展性,数据量增加的时候,支持水平扩展。
开源的日志系统
我们要构建一个企业级的日志系统的,一般选择的有免费的和收费的,收费的,云厂商的日志服务,我们今天不在考虑范围内。免费的开源的主要有:
日志的产生到使用,主要经过下面的阶段: 采集 -> 传输 -> 缓冲 -> 处理 -> 存储 -> 检索
ELK stack
ELK stack 是由 Elasticsearch、Logstash、Kibana 开源组件集合分析、搜索、展示的日志系统解决方案。
- Elatsicsearch 是全文搜索分析引擎
- Logstash 日志聚合器,收集和处理多种数据源的数据、转换并发送到其他目的地
- Kibana 用户界面,用于可视化的查询分析数据
- Beats 用于数据收集数据
GrayLog
GrayLog 也是一款开源的日志解决方案,本身 Graylog 提供了日志收集、日志存储搭配 MongoDB,查询层面依赖 Elasticsearch, Github 地址 github
- Graylog 提供对外接口,Web页面
- Elasticsearcg 日志文件的持久化存储和检索
- MongoDB 存储 Graylog 的配置
Graylog 一体化方案、方便、但是没有分层。因为不是 agent 方式,其支持的日志收集方式有 RestApi、UDP、TCP。 整体来说,通过构建 Input 来收集日志,每个 Input 可以单独配置 Extractors 来做字段转换。 当然还有其他的概念,诸如
- Inputs 日志抓取接收、由 Sidecar 主动抓取、或者其他服务主动上报的
- Extractors 日志数据格式解析转换, json解析、kv解析、时间戳解析、正则解析
- Streams 日志分类分组,将日志分类条件并发生到不同的索引文件中
- Indices 持久化存储,数据存储性能
- Outputs 日志数据转发,解析的 Stream 发送到其他的 Graylog 集群或服务
- Pipelines 日志数据过滤,建立数据清洗过滤规则、字段的添加删除、条件过滤、自定义函数等
- Sidecar 轻量级的日志采集器,适合大规模的适合使用
- Lookup Tables 服务解析,基于 IP 的 whois 查询 和 基于 来源IP 的监控
- Geolocation 可视化地理位置,基于 来源IP 的监控
Loki
Loki 是一个日志聚合系统,旨在纯纯和查询来自所有的应用程序和基础架构的日志。它与 prometheus 一样是可扩展、高可用、多租户的日志聚合系统,它不索引日志内容,只是为每个日志设置标签。
- 很简便
- 对象存储
- 结合 alert manager 生成报警
- 与 Prometheus、Grafana、K8S 原生集成
- 实时查看日志
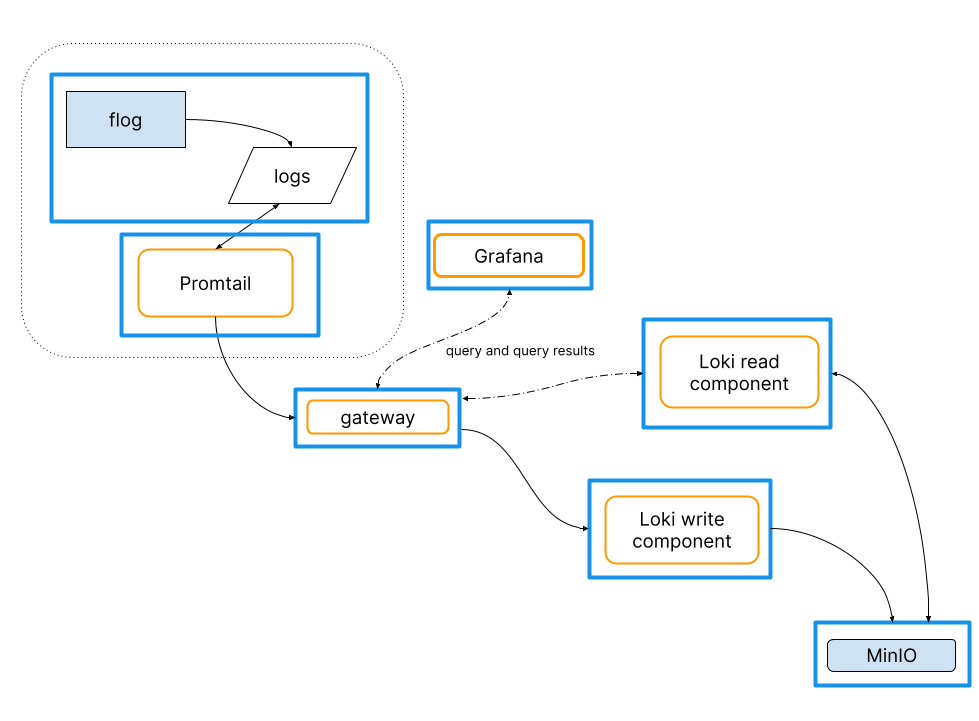
一个简单的使用 Loki 的组件,日志系统包含了几个
- promtail 客户端,抓取日志,通过网关推送给 Loki
- Minio 用于存储数据
- Grafana 提供 Loki 捕获的日志行的可视化
- …
- 静态标签支持的更好,标签应该具有有限的值。并且在查询日志的适合更有效与快速
- 谨慎使用动态标签,太多的标签会导致太多的流,这种会降低性能。在确实需要的时候,应该使用 过滤器 去查询
- 动态标签的化,请使用有界的值
- 使用 chunk_target_size 和 max_chunk_age 来合理控制区块大小 与 时间内区块数量
- 日志的时间顺序,当然 Loki 接受乱序的写入,但是针对一个日志,最好是顺序,否则后续的会使用新日志,如果是多个实例的,最好加上实例的host。 Promtail pipeline stage 可以从日志行提取时间,或者让 Promtail 为日志行分配时间戳
Loki 的几个核心配置
- 基本的配置
- HTTP 和 GRPC
- 服务发现 支持 consul、etcd
- 存储支持Local、GCS、AZURE、Swift、BOS(百度对象存储)
Loki支持客户端有哪些
- Promtail : Promtail是K8S首选,同一个节点的运行POD抓取日志。节点机器也可以使用 Promtail。
- Docker Driver :
- Fluentd 和 Fluent Bit : 当使用 Flentd 的时候,可以使用这个插件,选择 filter
- Logstash : 如果是 Logstash 或 beats,直接添加输出插件。
- Lambda Promtail : Loki 监控 AWS lambda 日志
- 非官方的 Go、Java、C#、Js、Python3
Loki 有一个可配置的存储模式 : 一个 from 标志着起点,在这个期间,该 schema都是活动状态,直到另一个条目具有了 新的 from 日期
WAL(Write Ahead Log)
Ingester 是将数据存在内存中,而 WAL机制可以弥补在发生奔溃的情况下导致的数据丢失的情况, WAL 是将数据存储在本地文件系统中, 重启的时候 Loki 将对数据进行 “重放”, 然后重放完毕后将自己注册为准备好了的,预备接收后续写入。一旦确认写入就不会丢失数据。
Loki 设计亮点
在 K8S 环境下的日志收集
不管以选择哪种日志方案、或者商业化的日志收集方案, 先看要收集哪些日志
- 系统 和 K8S 组件日志
/var/log/.. - 业务应用程序日志
自定义日志路径
涉及到 K8S 的日志采集、主要有以下几种方式
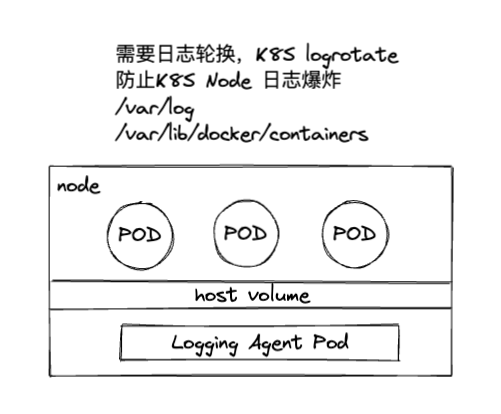
- Node 级日志代理 : 在每个宿主机上一个日志收集agent, 减少资源消耗、对应用无侵入。但是对于一些定制化的支持的不够
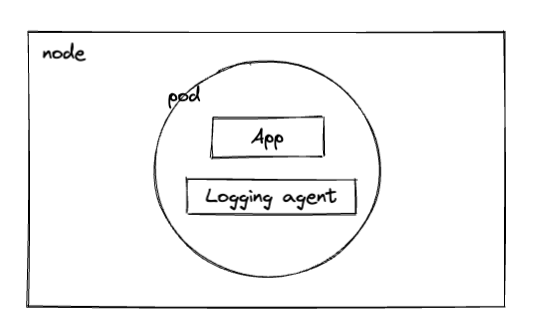
- Sidecar Container 作为日志代理 : 伴生容器,和应用容器在一个POD下, 专门收集应用日志,通过共享卷获取日志上传,也带来了额外的资源消耗,增加运营成本。但是低耦合。
- App 级直接上传日志 : 无需额外收集器、但同时也侵入应用了,增加应用复杂度。