算法 Bitmap
bitmap 原理
bitmap字面为位图映射, 原理是使用一个 bit 标记某个元素对应的 value,而 key 即该元素。因为只有一个 bit 来存储一个数据, 因而可以大大的节省空间。
数值映射:
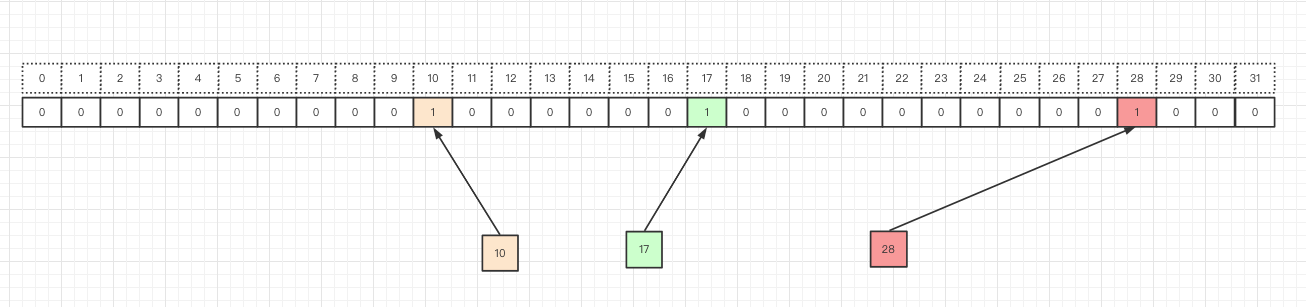
假如对 0-31 个内的3个元素(10, 17, 28)进行排序,可以采用
BitMap方法, 如下图, 对应的包含的位置将对应的值从0变更为1假如需要进行排序和检索,只需要依次遍历这个数据结构,碰到1的情况,数据存在
字符串映射:
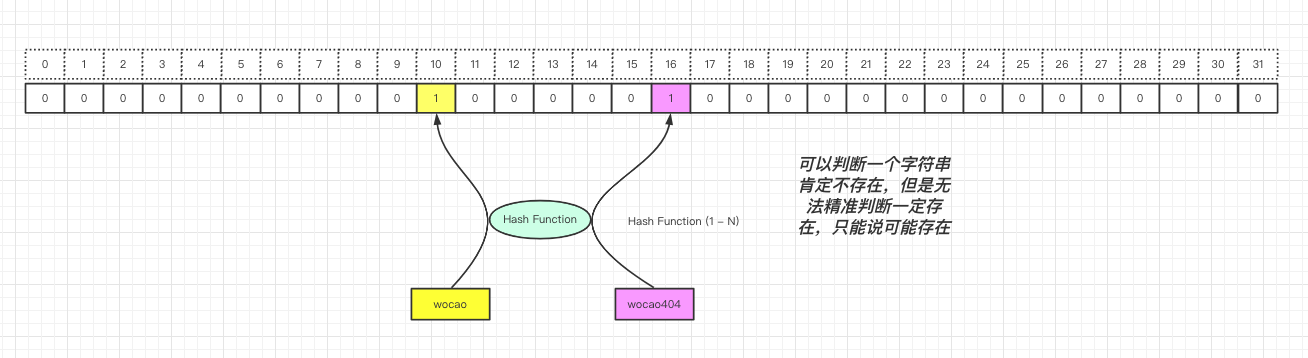
字符串也可映射,只不过需要经过一个
Hash步骤,通过映射关系可以判断字符串是否存在。但是因为Hash是将不确定长度的值变更为确定大小的值,存在Hash冲突性,所以一般要最大化的判断一个字符串是否真的存在,可以将这个字符串经过不同的Hash函数映射不同的位置。
bitmap 的 建立、查找、添加、删除、判断 原理
建立
Bitmap 的创建可以使用 byte 数组, 1 byte = 8 bit (也可使用 int 数组, 1 int = 32 bit, long 数组, 1 long = 64 bit)
也就是说到最后的数据的大小建立只需要创建 数组长度为
int[ 1 + N/32 ] byte[ 1 + N/8 ] long[ 1 + N/64 ]
即可存储,N表示要存储的最大的值。
下面我们都使用 int数组 表示
arr[0] 表述 0-31
arr[1] 表述 32-63
arr[2] 表述 64-95
...
查找
按照上面 int数组 的例子,要找到任意整数 M 映射到数组上的位置为 M / 32 得到下标,M % 32 得到它在这个下标对应的二进制的哪个位置
添加
我们将 5 这个数对应的值放入到 bitmap 中
5 / 32 = 0, 5 % 32 = 5 , 5 在 arr[0] 的第 5 个位置
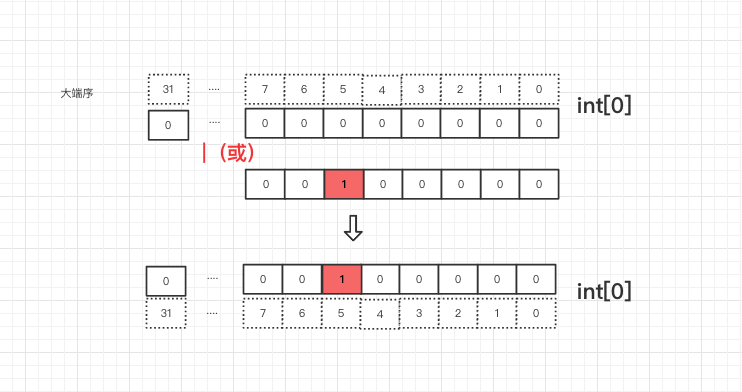
# 想插入一个数的值,只需要将 1 左移代表该数字的这一位( M % 32 )(备注:因为我这边是 int 类型,所以是 32 位), 然后与原来数字按位或
arr[0] = arr[0] | (1 << 5)
删除
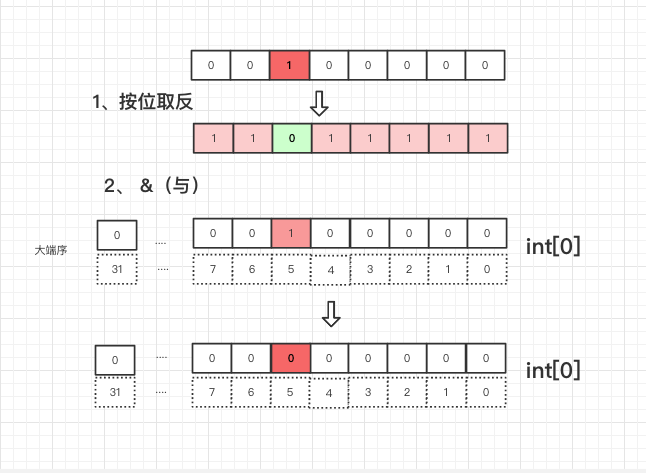
# 想插入一个数的值,只需要将 1 左移代表该数字的这一位( M % 32 )(备注:因为我这边是 int 类型,所以是 32 位), 然后取反后与原来数字按位与,则达到清除目的
arr[0] = arr[0] & (~(1 << 5))
判断
借助 查找 做定位,然后判断 当前位上的值是 0 还是 1 来达到判断的目的
bitmap 应用
大数据量快速排序
大数据量快速去重
大数据量快速查找
bitmap 的缺点 和 拓展
bitmap 的缺点还是有的 :
- 数据碰撞
字符串映射到 `bitmap`会有碰撞问题. - 数据稀松
比如要存入`(1,88888888,3333)`这三条数据, 我们要建立`99999999`长度的 `bitmap`,但实际上只存储了3条数据,浪费了空间.
(碰撞问题) Bloom Filter 和 Counting Bloom Filter
将任意大小的数据转换成特定大小的数据的函数.转换后的数据称为哈希值或哈希编码
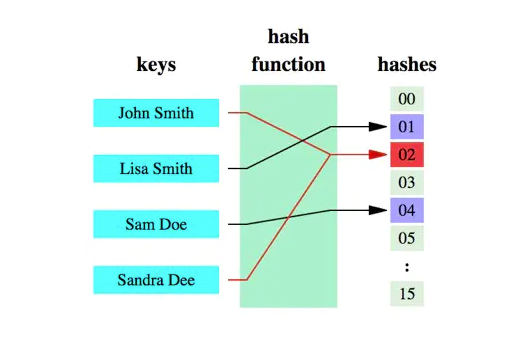
- 哈希函数是实现哈希表和布隆过滤器的基础
Bloom Filter
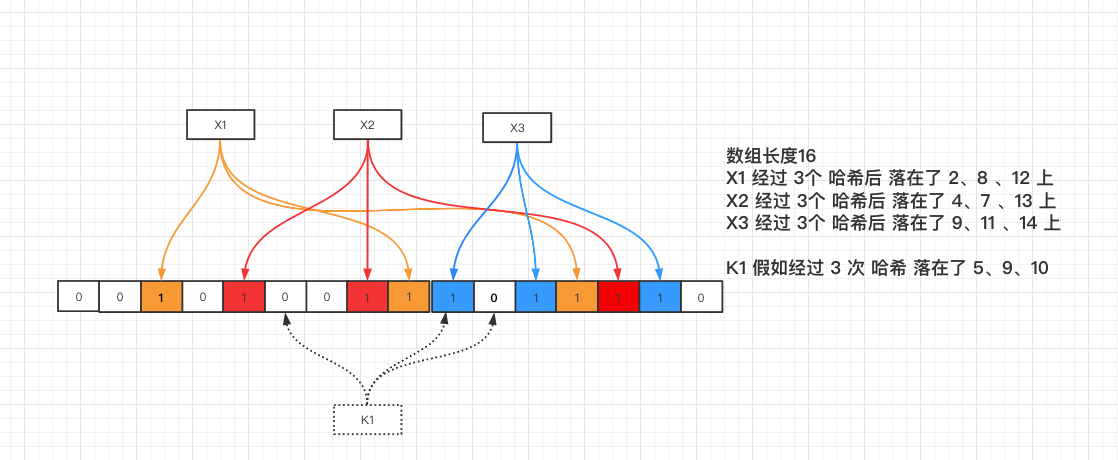
K1经过3次Hash落在地5、9、10上X3经过3次Hash落在9、11、14- 可以看出重叠点在
9上, 所以存在一定的误判
Counting Bloom Filter
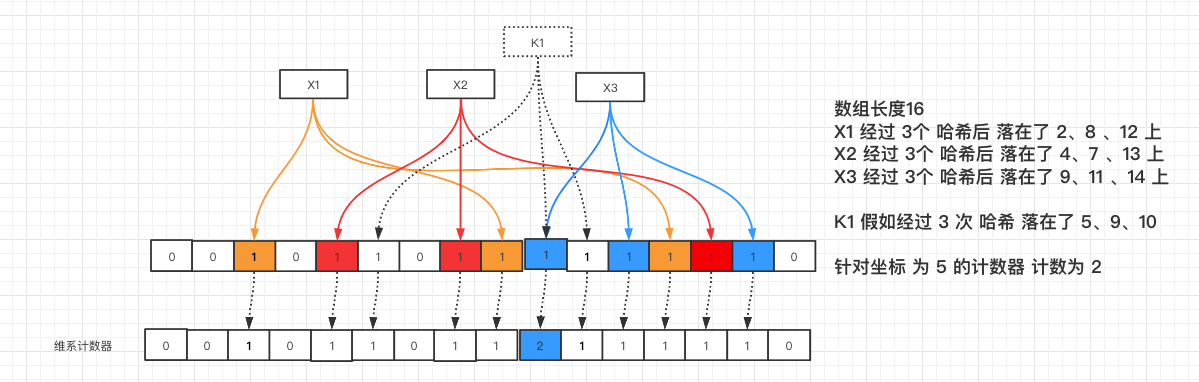
- 为了解决
bloom filter无法删除的问题 - 比正常的
bloom filter加入了对 位的计数器 - 当发生删除动作的时候,对应位置的
计数器-1
(稀松问题) Roaring BitMap
RoaringBitmap算法是将32位 的 int 类型数据划分位2^16个数据块,每个数据快对应整数的高16位,并使用一个容器(Container)来存放数值的低16位。RoaringBitmap将这些Container保存在一个动态数组中作为一级索引。RoaringBitmap的 Container 分类有 Array Container 和 Bitmap Container。Array Container存放稀疏数据,Bitmap Container存放稠密数据 (如果一个Container的整数数量小于4096,就用数组容器,若大于4096就用位图容器)。
Roaring BitMap 存储结构
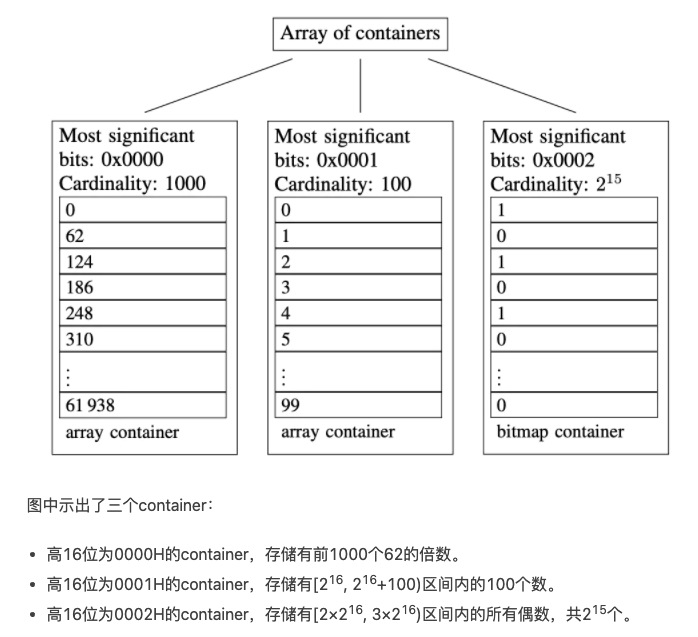
- 高16位为
0000H的 container,存储有前1000个62的倍数。 - 高16位为
0001H的 container,存储有[2^16, 2^16+100)区间内的100个数。 - 高16位为
0002H的 container,存储有[2×2^16, 3×2^16)区间内的所有偶数,共2^15个。
RoaringBitmap 结构
short[] keys;
Container[] values;
int size;
- 每个
32位的整形,高16位会被作为key存储到short[] keys中,低16位看作value存储到values中的某个Container中 keys和values通过下标一一对应keys数组永远保证有序,方便二分查找size标示了包含key-value pair的数量(即keys和values中有效数据的数量)
Array Container
当桶内数据基数 < 4096 的时候,采用它来存储, 数组初始长度伟为 4 随着数据增多会字段扩容, 最大长度为 4096。 在样例途中是 数组容器的 size 都没有超过 4096.
static final int DEFAULT_MAX_SIZE = 4096
short[] content;
- 低16位直接存入到
content中, 始终保证有序,方便二分查找。且不会存储重复数据。 - 因为没有数据压缩,适合存储少量的数据
Bitmap Container
当桶内数据基数 > 4096 的时候,采用它来存储. 是普通位图。用固定长度的 1024 的long数组并表示,即位图大小固定为 2^16 位 (8KB)
long[] bitmap; // 每个bitmap初始化长度都是固定的 1024 的 long[]
- 每个
Container处理 16位的整形数据,也就是0-65535。 - 根据
bitmap原来,需要存储65535 个bit的存储数据,每个比特位用1表示有, 用0表示无。 每个 long 有 64 bit, 需要1024个 long来提供65536个bit。(8KB)
Run Container
short[] valuesLength; //存储的是压缩后的数据
int nbrruns = 0;
Run Container中的Run指的是游(行)程长度压缩算法(Run Length Encoding),对连续数据有比较好的压缩效果.原理:
- 对于数列
11, 压缩为 11,0 - 对于数列
11,12,13,14,15, 压缩为11,4 - 对于数列
11,12,13,14,15,21,22, 压缩为11,4,21,1
- 对于数列
- 压缩算法的性能和数据的连续性关系极为密切,对于
连续的100 short, 它能从200 bit压缩到4 bit,但是对于完全不连续的 100 short,编码完后200 bit变成400 bit- 最好情况: 只存在一个数据或者只存在一串连续的数字, 那么只会存储
2 个 short,占有4 bit - 最坏情况:
0-65535范围内填充所有的奇数位(或所有的偶数位), 需要存储65536 个 short,128KB
- 最好情况: 只存在一个数据或者只存在一串连续的数字, 那么只会存储
时间空间分析
时间
- 增删改查方面
Bitmap Container只涉及位运算 O(1) Array Container和Run Container都是二分查找有序数组定位元素O(logN)空间Bitmap Container恒定8192BArray Container空间于基数(c)有关,(2+2c)BRun Container空间与存储的 连续序列数(r) 有关,(2+4r)B