Kafka与Debezium构建CDC管道
建设篇
1、什么是 debezium?
Tutorial https://debezium.io/documentation/reference/1.3/tutorial.html
2、Debezium 如何工作的
2.1 Debezium 支持的数据库类型
- MySQL
- MongoDB
- PostgreSQL
- Oracle
- SQL Server
- Db2
- Cassandra
2.2 Debezium 三种方式运行
- Kafka Connect
- Debezium Server
- Embedded Engine
https://github.com/debezium/debezium-examples/tree/master/kinesis
3、在 K8S 中构建基础Debezium集群环境
镜像准备
- kafka | debezium https://hub.docker.com/r/debezium/kafka
- zookeeper | debezium https://hub.docker.com/r/debezium/zookeeper
- connect | debezium https://hub.docker.com/r/debezium/connect
- schema-registry | confluentinc https://hub.docker.com/r/confluentinc/cp-schema-registry
ps: debezium 参考地址 https://github.com/debezium/docker-images confluentinc 参考地址 https://github.com/confluentinc/cp-all-in-one/tree/latest/cp-all-in-one
3.1 K8S基础知识
- kafka 与 zookeeper 建设为 stateful 状态集群
- schema-registry 主要为了 支持 avro 格式这些不需要写到 kafka 消息头里面,减少消息的大小,额外的服务,属于 kafka 生态,存储依赖 kafka broker保证稳定性。
- k8s steteful 集群 0…~ n 个 POD
- zookeeper 里面 zoo.cfg 指定的是从 1 开始
- kafka 里面 broker 也是从 1 开始
3.2 zookeeper 构建
- 对应的 docker-entrypoint.sh 需要改写,注重 zoo.cfg 的生成
- 开放 2888 端口 3888 端口 2181 端口
# 使用的 debezium zk 镜像
# https://github.com/debezium/docker-images/blob/master/zookeeper/1.4/README.md
apiVersion: v1
kind: Service
metadata:
name: zookeeper-hs
labels:
app: zookeeper
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
- port: 2181
name: client
clusterIP: None
selector:
app: zookeeper
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zookeeper
spec:
selector:
matchLabels:
app: zookeeper
serviceName: zookeeper-hs
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: OrderedReady
template:
metadata:
labels:
app: zookeeper
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zookeeper
topologyKey: "kubernetes.io/hostname"
securityContext:
fsGroup: 1000
runAsUser: 1000
containers:
- name: zookeeper
imagePullPolicy: Always
image: debezium/zookeeper:1.3
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
resources:
requests:
cpu: 50m
memory: 1500Mi
command:
- bash
- -ec
- |
if [ ! -d "/zookeeper/zdata/data" ];then
mkdir /zookeeper/zdata/data
fi
if [ ! -d "/zookeeper/zdata/txns" ];then
mkdir /zookeeper/zdata/txns
fi
export INDEX=${HOSTNAME##*-}
echo $INDEX
export SERVER_ID=$(( INDEX + 1 ))
export SERVER_COUNT=3
export LOG_LEVEL=INFO
cp -rn $ZK_HOME/conf.orig/* $ZK_HOME/conf
sed -i -r -e "s|\\$\\{zookeeper.root.logger\\}|$LOG_LEVEL, CONSOLE|g" $ZK_HOME/conf/log4j.properties
sed -i -r -e "s|\\$\\{zookeeper.console.threshold\\}|$LOG_LEVEL|g" $ZK_HOME/conf/log4j.properties
echo "" >> $ZK_HOME/conf/zoo.cfg
echo "#Server List" >> $ZK_HOME/conf/zoo.cfg
for i in $( eval echo {1..$SERVER_COUNT});do
export HS_INDEX=$((i - 1))
if [ "$SERVER_ID" = "$i" ];then
echo "server.$i=0.0.0.0:2888:3888" >> $ZK_HOME/conf/zoo.cfg
else
echo "server.$i=zookeeper-$HS_INDEX.zookeeper-hs:2888:3888" >> $ZK_HOME/conf/zoo.cfg
fi
done
echo ${SERVER_ID} > $ZK_HOME/zdata/data/myid
sed -i "s|/zookeeper/data|/zookeeper/zdata/data|g" $ZK_HOME/conf/zoo.cfg
sed -i "s|/zookeeper/txns|/zookeeper/zdata/txns|g" $ZK_HOME/conf/zoo.cfg
export ZOOCFGDIR="$ZK_HOME/conf"
export ZOOCFG="zoo.cfg"
exec $ZK_HOME/bin/zkServer.sh start-foreground
volumeMounts:
- name: zk-data
mountPath: /zookeeper/zdata
volumeClaimTemplates:
- metadata:
name: zk-data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: alicloud-disk-efficiency
resources:
requests:
storage: 20Gi
---
apiVersion: v1
kind: Service
metadata:
name: zookeeper-hs
labels:
app: zookeeper
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
- port: 2181
name: client
clusterIP: None
selector:
app: zookeeper
参考文档 https://github.com/debezium/docker-images/blob/master/zookeeper/1.3/README.md
3.3 kafka 构建
- Kafka BrokerID 要变更,通过 POD 的 Index
- KAFKA_LISTENERS 与 KAFKA_ADVERTISED_LISTENERS 的配置
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka
spec:
selector:
matchLabels:
app: kafka
serviceName: kafka
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: OrderedReady
template:
metadata:
labels:
app: kafka
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- kafka
topologyKey: "kubernetes.io/hostname"
securityContext:
fsGroup: 1000
runAsUser: 1000
containers:
- name: kafka
imagePullPolicy: Always
image: debezium/kafka:1.3
ports:
- containerPort: 9092
- containerPort: 9093
resources:
requests:
cpu: 100m
memory: 1500Mi
env:
- name: ZOOKEEPER_CONNECT
value: "zookeeper-0.zookeeper-hs:2181,zookeeper-1.zookeeper-hs:2181,zookeeper-2.zookeeper-hs:2181"
- name: LOG_LEVEL
value: "INFO"
- name: KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR
value: "2"
- name: KAFKA_LISTENER_SECURITY_PROTOCOL_MAP
value: "PLAINTEXT:PLAINTEXT,EXTERNAL_PLAINTEXT:PLAINTEXT"
- name: KAFKA_INTER_BROKER_LISTENER_NAME
value: "PLAINTEXT"
- name: KAFKA_LISTENERS
value: "PLAINTEXT://0.0.0.0:9092,EXTERNAL_PLAINTEXT://0.0.0.0:9093"
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
command:
- bash
- -ec
- |
export INDEX=${HOSTNAME##*-}
export BROKER_ID=$((INDEX + 1))
PORT=$((INDEX + 9093))
export JMX_PORT=$((INDEX + 9999))
export KAFKA_ADVERTISED_LISTENERS="PLAINTEXT://${POD_IP}:9092,EXTERNAL_PLAINTEXT://${LB_IP}:${PORT}"
exec /docker-entrypoint.sh start
volumeMounts:
- name: kafka-data
mountPath: /kafka/data
volumeClaimTemplates:
- metadata:
name: kafka-data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: alicloud-disk-efficiency
resources:
requests:
storage: 20Gi
---
apiVersion: v1
kind: Service
metadata:
name: kafka-{index}
annotations:
# 参考阿里云LB Service 配置 自动创建 好几种 LB类型,这边是内网LB
service.beta.kubernetes.io/alicloud-loadbalancer-address-type: intranet
service.beta.kubernetes.io/alicloud-loadbalancer-id: {LB实例ID}
service.beta.kubernetes.io/alicloud-loadbalancer-force-override-listeners: 'true'
spec:
externalTrafficPolicy: Local
type: LoadBalancer
selector:
statefulset.kubernetes.io/pod-name: kafka-{index}
ports:
- name: external
port: {{ 9093 + index }}
protocol: TCP
targetPort: 9093
- name: jmx
port: {{ 9999 + index }}
protocol: TCP
targetPort: {{ 9999 + index }}
- name: internal
port: 9092
protocol: TCP
targetPort: 9092
---
piVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: kafka-manager
annotations:
nginx.ingress.kubernetes.io/enable-global-auth: "false"
spec:
rules:
- host: kafka-manager.{域名}.com
http:
paths:
- path: /
backend:
serviceName: kafka-manager
servicePort: 80
---
apiVersion: v1
kind: Service
metadata:
name: kafka-manager
labels:
app: kafka-manager
spec:
ports:
- name: http
port: 80
targetPort: 9000
selector:
app: kafka-manager
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-manager
labels:
app: kafka-manager
spec:
replicas: 1
selector:
matchLabels:
app: kafka-manager
template:
metadata:
labels:
app: kafka-manager
spec:
containers:
- name: kafka-manager
imagePullPolicy: Always
image: dockerkafka/kafka-manager
ports:
- containerPort: 9000
env:
- name: ZK_HOSTS
value: "zookeeper-0.zookeeper-hs:2181,zookeeper-1.zookeeper-hs:2181,zookeeper-2.zookeeper-hs:2181"
resources:
requests:
cpu: 40m
memory: 500Mi
参考文档 https://github.com/debezium/docker-images/blob/master/kafka/1.4/README.md
3.3 kafka schema-registry 构建
- Docker 基础镜像环境启动脚本 https://github.com/confluentinc/schema-registry-images/blob/master/schema-registry/include/etc/confluent/docker/
- 先启动 pod 再映射 service,否则启动报错, 在这个项目里面有个 SCHEMA_REGISTRY_PORT,在基础启动脚本里面会主动退出
- 配置 ZK 的话,在kafka listener 里面要有类型 PLAINTEXT, 集群内网外网环境配置了 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP,按照正常的Kafka是正常的,但是 schema-registry 实现的是没有去找的,未做映射,只要没有 PLAINTEXT 就报错退出,启动失败
apiVersion: apps/v1
kind: Deployment
metadata:
name: schema-registry
labels:
app: schema-registry
spec:
replicas: 1
selector:
matchLabels:
app: schema-registry
template:
metadata:
labels:
app: schema-registry
spec:
securityContext:
fsGroup: 1000
runAsUser: 1000
containers:
- name: schema-registry
imagePullPolicy: Always
image: confluentinc/cp-schema-registry:6.0.0
ports:
- containerPort: 8081
env:
- name: SCHEMA_REGISTRY_HOST_NAME
value: schema-registry
- name: SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL
value: zookeeper-0.zookeeper-hs:2181,zookeeper-1.zookeeper-hs:2181,zookeeper-2.zookeeper-hs:2181
- name: SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS
value: kafka-0:9092,kafka-1:9092,kafka-2:9092
resources:
requests:
cpu: 40m
memory: 500Mi
---
apiVersion: v1
kind: Service
metadata:
name: schema-registry
labels:
app: schema-registry
spec:
ports:
- name: http
port: 8081
selector:
app: schema-registry
参考文档 https://github.com/confluentinc/cp-all-in-one/blob/latest/cp-all-in-one-cloud/docker-compose.yml
3.3 kafka connect 建设
apiVersion: v1
kind: Service
metadata:
name: connect
labels:
app: connect
spec:
ports:
- name: http
port: 80
targetPort: 8083
selector:
app: connect
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: connect
labels:
app: connect
spec:
replicas: 3
selector:
matchLabels:
app: connect
template:
metadata:
labels:
app: connect
spec:
containers:
- name: connect
imagePullPolicy: Always
image: debezium/connect:1.3
ports:
- containerPort: 8083
env:
- name: LOG_LEVEL
value: "INFO"
- name: BOOTSTRAP_SERVERS
value: "kafka-0:9092,kafka-1:9092,kafka-2:9092"
- name: GROUP_ID
value: "test_connect"
- name: CONFIG_STORAGE_TOPIC
value: "test_connect_configs"
- name: OFFSET_STORAGE_TOPIC
value: "test_connect_offset"
- name: STATUS_STORAGE_TOPIC
value: "test_connect_status"
- name: KEY_CONVERTER
value: "io.confluent.connect.avro.AvroConverter"
- name: VALUE_CONVERTER
value: "io.confluent.connect.avro.AvroConverter"
- name: INTERNAL_KEY_CONVERTER
value: "org.apache.kafka.connect.json.JsonConverter"
- name: INTERNAL_VALUE_CONVERTER
value: "org.apache.kafka.connect.json.JsonConverter"
- name: CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_UR
value: "http://schema-registry:8081"
- name: CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_UR
value: "http://schema-registry:8081"
resources:
requests:
cpu: 40m
memory: 500Mi
# 使用 kafka-connect-ui构建
---
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: kafka-connect-ui
annotations:
nginx.ingress.kubernetes.io/enable-global-auth: "false"
spec:
rules:
- host: kafka-connect.{域名}.com
http:
paths:
- path: /
backend:
serviceName: kafka-connect-ui
servicePort: 80
---
apiVersion: v1
kind: Service
metadata:
name: kafka-connect-ui
labels:
app: kafka-connect-ui
spec:
ports:
- name: http
port: 80
targetPort: 8000
selector:
app: kafka-connect-ui
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-connect-ui
labels:
app: kafka-connect-ui
spec:
replicas: 1
selector:
matchLabels:
app: kafka-connect-ui
template:
metadata:
labels:
app: kafka-connect-ui
spec:
containers:
- name: kafka-connect-ui
imagePullPolicy: Always
image: landoop/kafka-connect-ui
ports:
- containerPort: 8000
env:
- name: CONNECT_URL
value: "http://connect"
resources:
requests:
cpu: 40m
memory: 500Mi
参考文档
- https://github.com/debezium/docker-images/blob/master/connect/1.4/README.md
- https://github.com/debezium/debezium-examples/blob/master/tutorial/docker-compose-mysql-avro-connector.yaml
数据湖篇
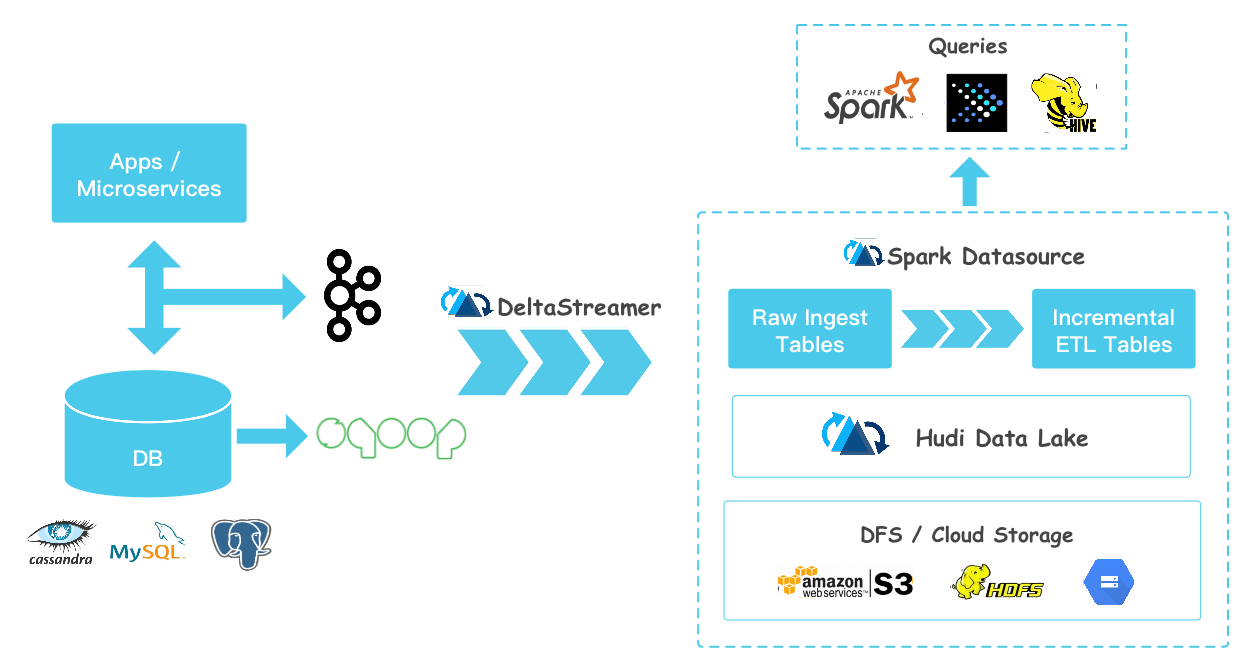
1、Hudi Data Lake?
之前构建了基于 Debezium 捕获基本的数据变化,发送至 Kafka, 后面的对接方可以是哪些呢?这些是要处理的……
Apache Hudi 是构建在 HDFS/S3 等大数据量的存储,旨在解决大数据生态系统中需要插入更新及增量消费的摄取管道和 ETL管道的低效问题。
Near Real-Time Ingestion (近实时获取)
将数据从外部数据
event logs, databases, external sources提取到Hadoop Data Lake。 对于RDBMS摄取,Hudi通过Upserts提供了更快的负载,Near Real-time Analytics (近实时分析)
Hadoop上的交互式SQL解决方案(如Presto和SparkSQL)。通过Hudi将数据的更新时间缩短至几分钟,还可以对存储在DFS中的多个大小更大的表进行实时分析。 而且,Hudi没有外部依赖项(如HBase群集),因此可以在不增加运营开销的情况下,对更新鲜的分析进行更快的分析。Incremental Processing Pipelines (增量处理管道)
Data Dispersal From DFS (分散数据)
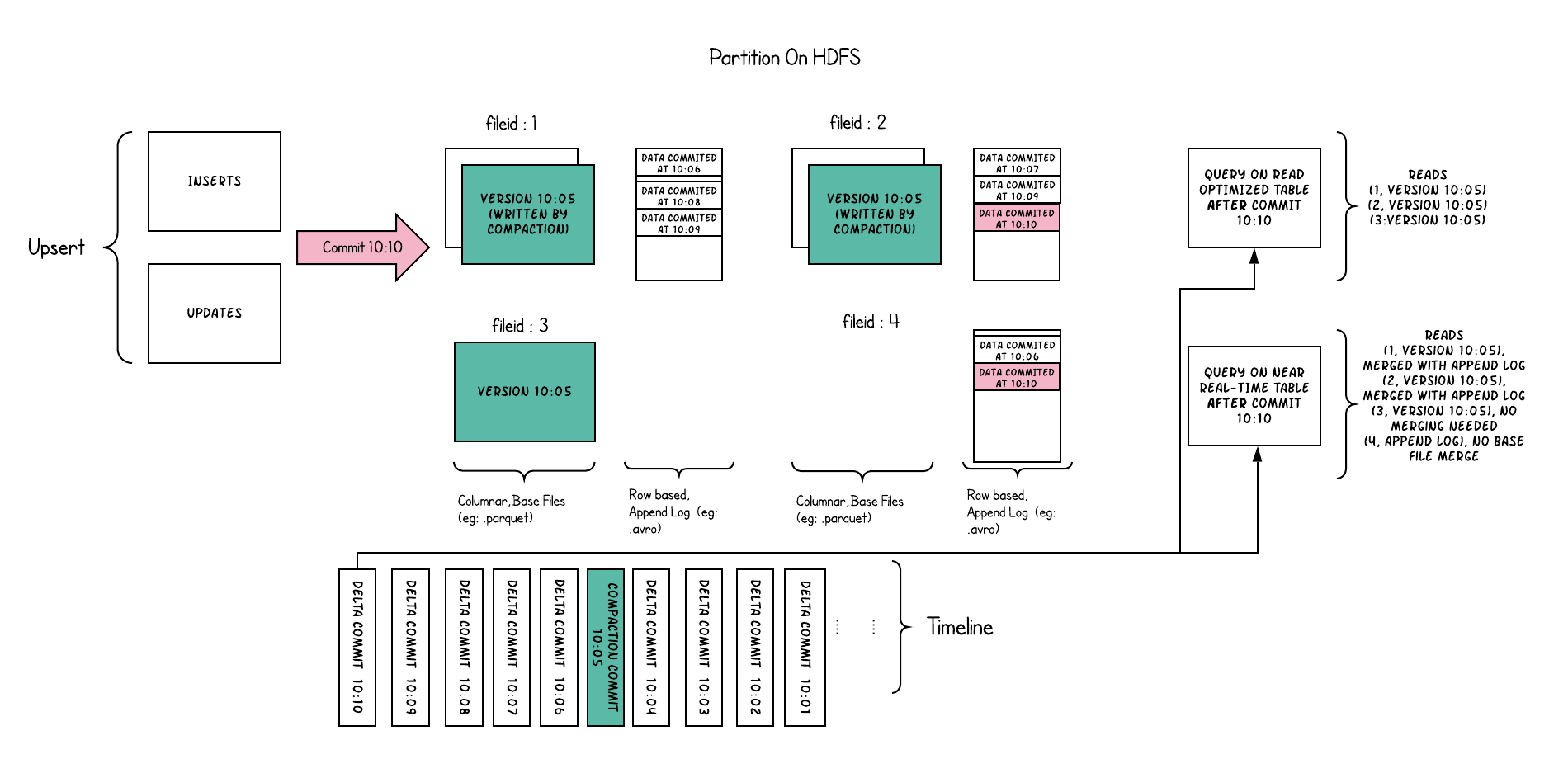
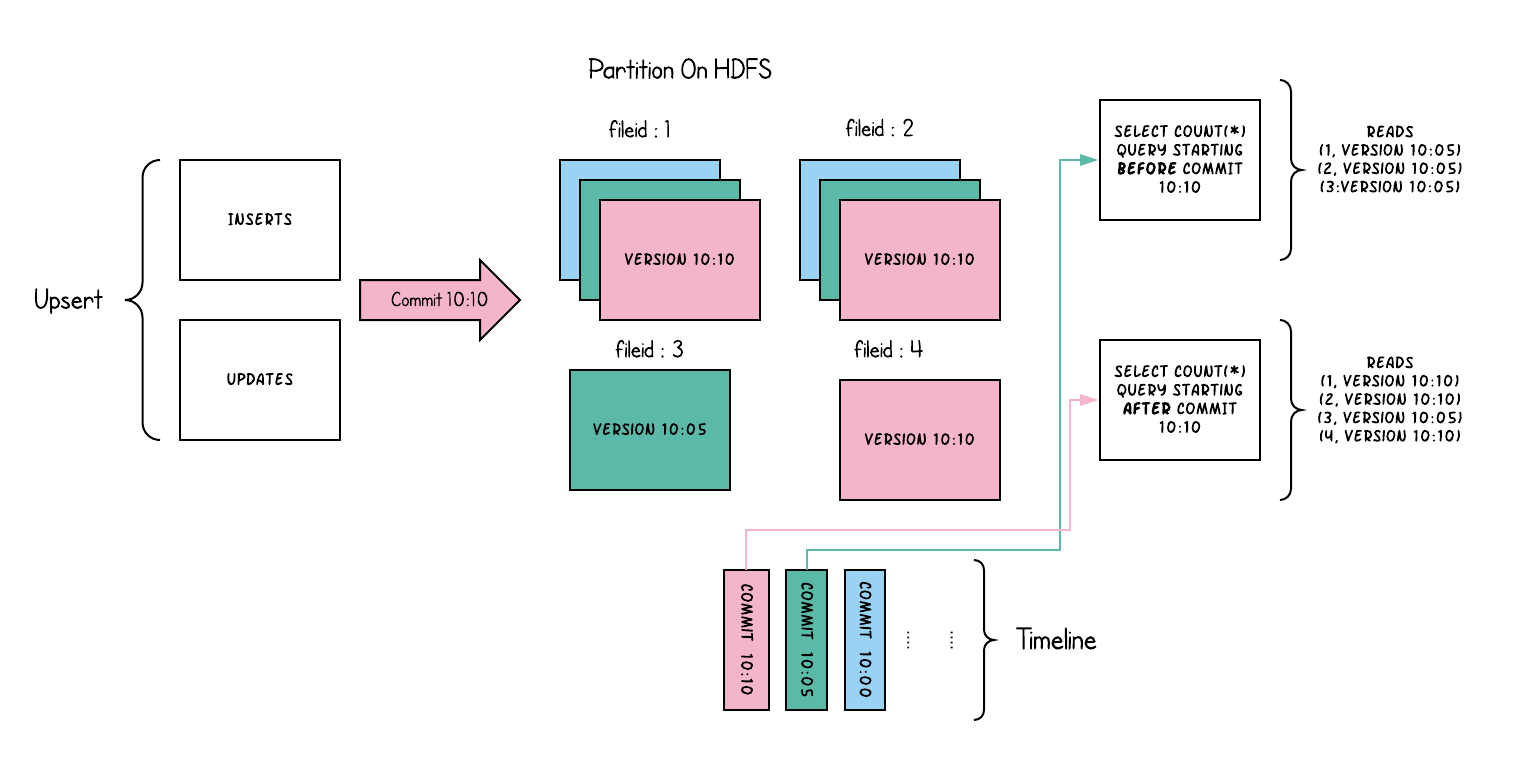
2、Timeline
Hudi的核心是维护timeline在不同instants时间上对表上执行的所有操作中一个操作,这有助于提供表的即时视图,
同时还有效地支持按到达顺序对数据进行检索。
Hudi瞬间包含以下组件
- Instant action :在表格上执行的操作类型
- Instant time :即时时间通常是一个时间戳记(例如:20190117010349),该时间戳记以动作开始时间的顺序单调增加。
- state :即时状态
Hudi保证在timeline上执行的操作基于当前时间是原子性和时间轴上一致的。
执行的关键动作包括
- COMMITS - 提交记录 一批记录原子写入表中 提交表示将一批记录原子写入表中。
- CLEANS - 后台清除表中不需要的文件旧版本记录。
- DELTA_COMMIT - 增量提交是指将一批记录原子写入
MergeOnRead类型表中,其中一些/所有 数据 可以只写到增量日志中。 - COMPACTION - 调和
Hudi中不同数据结构的后台活动,例如:将更新从基于行的日志文件移动到列格式。在内部,压缩表现为时间轴上的特殊提交 - ROLLBACK - 表示提交/增量提交不成功且已回滚,删除了在写入过程中产生的任何部分文件
- SAVEPOINT - 将某些文件组标记为“已保存”,以便清理程序不会删除它们。在发生灾难/数据恢复的情况下,它有助于将表还原到时间轴上的某个点。
任何给定的瞬间都可以处于以下状态之一
- REQUESTED -表示已经安排了动作,但尚未开始
- INFLIGHT -表示当前正在执行该操作
- COMPLETED -表示在时间表上完成了一项操作
3、Hudi 的存储类型
COW Copy On Write 快照查询 + 增量查询
数据仅仅以 列文件格式 parquet 存储,每次写操作后数据的同步 Merge 以更新版本并重写文件,COW表中数据使用是最新的
MOR merge on read 快照查询 + 增量查询 + 读取优化
数据以 列文件格式 parquet 和 基于 行文件格式 avro 组合存储。每次写入操作将增量创建文件。然后 compact 以生成 列文件 的最新版