回望K8S 容器编排与Kubernetes作业管理
Pod
pod 是 Kubernetes 项目的最小的 API 对象,原子调度单位.
假设 “容器的本质是进程”,容器镜像就是 exe 安装包, kubernetes 是操作系统
Pod 最重要的一个事实是一个逻辑概念。它对于 Kubernetes 最核心的意义是 容器设计模式。Kubernetes 真正处理的还是宿主机上操作系统上的 Linux 容器的 Namespace 和 Cgroups,而不是一个所谓的 Pod 边界和隔离环境。
Pod 其实是一组共享了某些资源的容器。Pod 里面所有的容器,共享的同一个 Network Namespace,并且可以声明共享同一个 Volume.
Kubernetes 项目内部,Pod 实现需要使用一个中间容器,这个容器叫做 Infra 容器,在 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起。
sidecar
典型的例子:WAR 包和 Web 服务器
POD后,将 WAR 包和 Tomcat 分别做成镜像,可以把他们容器结合在一起
---
apiVersion: v1
kind: Pod
metadata:
name: javaweb-2
spec:
# 启动后做了一件事 把应用的WAR包拷贝到 /app目录中,后退出
initContainers:
- image: sample-war:v2
name: war
command: ["cp", "/sample.war", "/app"]
volumeMounts:
- mountPath: /app
name: app-volume
containers:
- image: tomcat:7.0
name: tomcat
command: ["sh","-c","/root/apache-tomcat-7.0.42-v2/bin/start.sh"]
volumeMounts:
- mountPath: /root/apache-tomcat-7.0.42-v2/webapps
name: app-volume
ports:
- containerPort: 8080
hostPort: 8001
volumes:
- name: app-volume
emptyDir: {}
...
这个POD中,定义了两个容器,第一个容器镜像 sample-war:v2,第二个容器镜像是 Tomcat 镜像,War包容器的类型不是一个普通容器,是一个 Init Container 类型的容器。
在Pod中,所有 Init Container 定义的容器,都比 spec.containers 定义的用户容器先启动。并且, Init Container 容器会按顺序准一启动,而直到他们都启动并且退出了,用户容器才会启动。
这种组合的方式,正是容器设计模式里面最常用的一种模式:sidecar
容器的日志收集
应用把日志文件输出到容器的 /var/log 目录中,Pod的 Volume 挂载到应用容器的 /var/log 目录上,然后在这个 Pod 里的运行一个 sidecar 容器,也声明挂载同一个 Volume 到自己的 /var/log 目录上,
这样这个 sidecar 容器只需要做一件事,把自己的 /var/log 目录中读取日志文件,转发就可以了,就是一个基本的日志收集
Pod 对象的基本概念
Pod 是容器环境的 Kubernetes 的基本单元,调度、网络、存储、以及安全相关的熟悉,都是属于 Pod 级别的。
Pod 下重要的字段和含义
NodeSelector: 用户将Pod和Node绑定的字段NodeName: 一旦Pod的这个阻断被赋值,K8S会认为这个Pod已经经过调度。HostAliases:定义了Pod的hosts文件(比如/etc/hosts)里的内容
凡是跟容器的 Linux Namespace 相关的属性,也一定是 Pod 级别的。
shareProcessNamespace=true
Pod 对象在 Kubernetes 中的生命周期。Pod 生命周期的变化,主要体现在 Pod API 对象的 Status 部分,这是它除了 Metadata 和 Spec 之外的第三个重要字段。其中,pod.status.phase,就是 Pod 的当前状态,
它有如下几种可能的情况:
Pending。这个状态意味着,Pod的YAML文件已经提交给了Kubernetes,API对象已经被创建并保存在Etcd当中。但是,这个Pod里有些容器因为某种原因而不能被顺利创建。比如,调度不成功。Running。这个状态下,Pod已经调度成功,跟一个具体的节点绑定。它包含的容器都已经创建成功,并且至少有一个正在运行中。Succeeded。这个状态意味着,Pod里的所有容器都正常运行完毕,并且已经退出了。这种情况在运行一次性任务时最为常见。Failed。这个状态下,Pod里至少有一个容器以不正常的状态(非 0 的返回码)退出。这个状态的出现,意味着你得想办法Debug这个容器的应用,比如查看Pod的Events和日志。Unknown。这是一个异常状态,意味着Pod的状态不能持续地被kubelet汇报给kube-apiserver,这很有可能是主从节点(Master和Kubelet)间的通信出现了问题。
Kubernetes 其他对象 Volume
Kubernetes 支持的 Project Volume 一共有四种:
Secret: 把 Pod 想要访问的加密数据,存放到Etcd中,然后通过在 Pod 的容器里挂载 Volume 的方式。ConfigMap: 保存的是不需要加密的、应用所需的配置信息。而ConfigMap的用法几乎与Secret完全相同:你可以使用kubectl create configmap从文件或者目录创建ConfigMap,也可以直接编写ConfigMap对象的YAML文件。Downward API: 让 Pod 里的容器能够直接获取到这个Pod API对象本身的信息。一定是 Pod 里的容器进程启动之前就能够确定下来的信息。而如果你想要获取 Pod 容器运行后才会出现的信息,比如,容器进程的
PID,那就肯定不能使用Downward API了,而应该考虑在Pod里定义一个sidecar容器。ServiceAccountToken: 这种把Kubernetes客户端以容器的方式运行在集群里,然后使用default Service Account自动授权的方式,被称作“InClusterConfig”.
---
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
user: YWRtaW4=
pass: MWYyZDFlMmU2N2Rm
...
> kubectl create secret
容器的健康检查和恢复机制
Pod 容器定义了一个健康检查的"探针"(Probe), 这样kubelet就会根据这个 probe 返回的值决定这个容器的状态,而不是直接以容器镜像十分运行来作为依据。生产环境保证应用健康存活的重要手段。
Pod 恢复机制 restartPolicy, 它是 Pod 的 Spec 部分的一个标准字段(pod.spec.restartPolicy),默认值是 Always,即:任何时候这个容器发生了异常,它一定会被重新创建。
pod恢复,永远只发生在当前节点,而不会跑到别的节点上去。(不会发生故障转移)需要转移的需要切换到Deployment这样的控制器来管理POD
你还可以通过设置 restartPolicy,改变 Pod 的恢复策略。除了 Always,它还有 OnFailure 和 Never 两种情况:
Always:在任何情况下,只要容器不在运行状态,就自动重启容器;OnFailure: 只在容器 异常时才自动重启容器;Never: 从来不重启容器。
编排其实很简单-“控制器"模型
前面已经知道 POD 是一个复杂的API对象,实际也是对容器的进一步抽象和封装;也就是说Pod对象是容器的升级版,它对容器的组合,添加了很多的属性和字段。
Kubernetes操作POD是依赖控制器(Controller)完成的。就是 kube-controller-manager 组件
通过查看 https://github.com/kubernetes/kubernetes/tree/master/pkg/controller 源代码下能看见这些目录
deployment/ job/ podautoscaler/ cloud/ disruption/ namespace/
replicaset/ serviceaccount/ volume/cronjob/ garbagecollector/ nodelifecycle/
replication/ statefulset/ daemon/...
这些每个目录都是一种类型的 controller,各自负责某种编排功能。
控制循环(control loop)
for {
实际状态 := 获取集群中对象X的实际状态(Actual State)
期望状态 := 获取集群中对象X的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}
具体实现时候,实际状态来自于Kubernetes 集群本身,期望状态来自于用户提交的 YAML 文件。
比如
Deployment控制器从Etcd中获取到目标标签的POD,然后统计他们的数量,这是实际状态;Deployment对象的Replicas字段的值是期望状态;Deployment控制器将两个状态做比较,然后根据比较结果,确定创建POD还是删除已经存在的POD
这个操作叫做协调(Reconcile)即 控制循环
为什么是循环,因为事件往往是一次性的,如果操作失败比较难处理,但是控制器循环一直尝试,更符合 Kubernetes 声明式API,最终达成一致。

上半部分的控制器定义(包含期望状态),下面的部分被控制对象的模板组成的。
作业副本和水平扩展
Pod 的“水平扩展 / 收缩”(horizontal scaling out/in)
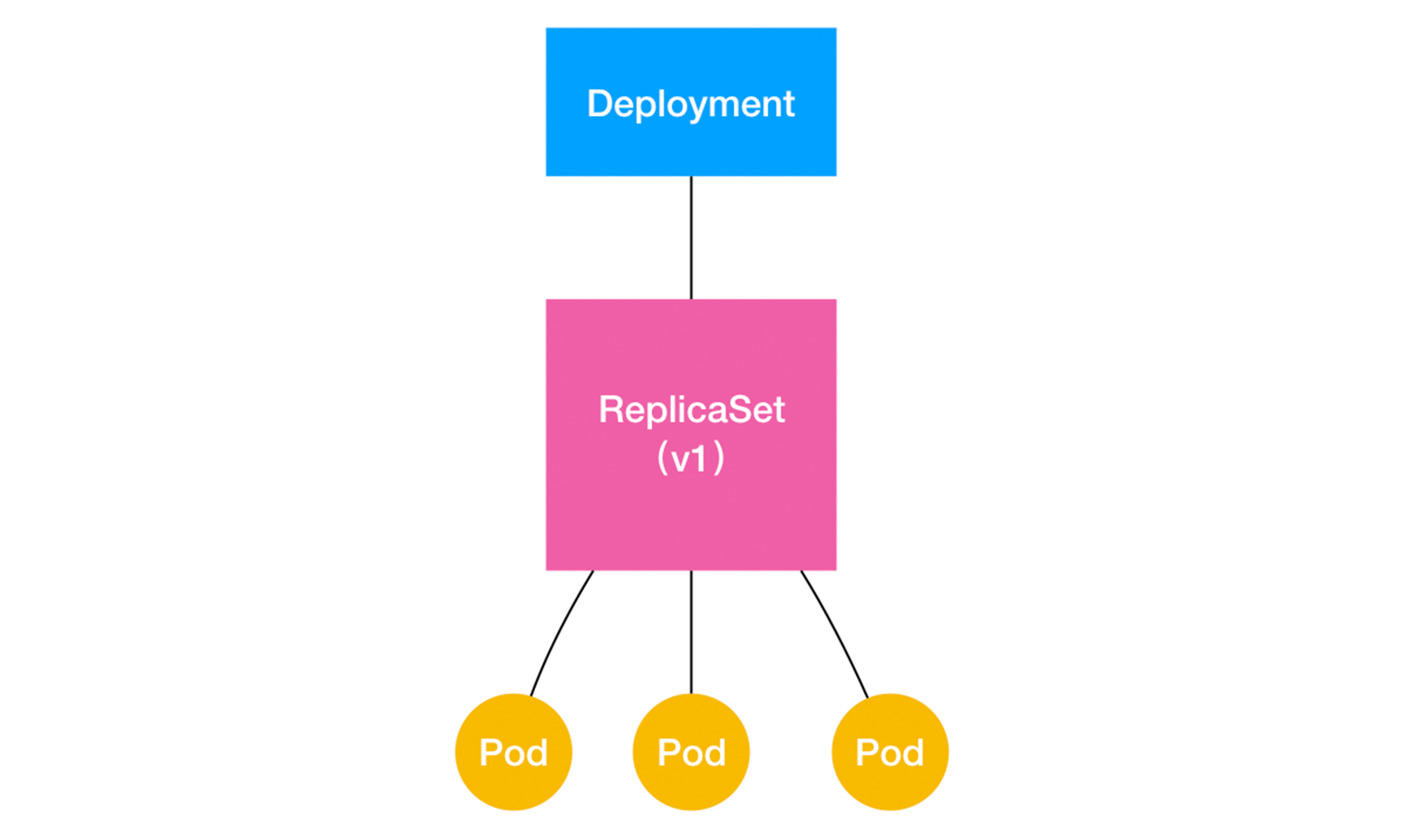
如果我们更新了 Deployment 的 Pod 模板(假如更新了容器镜像),那么 Deployment 需要遵循一种 “滚动更新”(rolling update)的方式来升级现有的容器。这也是 kubernetes 重要的概念(API对象):ReplicaSet
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-set
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
一个 ReplicaSet对象,由 副本数目的定义和一个Pod模板组成的。它其实是 Deployment 的子集。而且,Deployment控制器操作的正是 ReplicaSet 对象,而不是Pod对象。
kubectl scale
滚动更新
将一个集群中正在运行的多个 Pod 版本,交替地逐一升级的过程,就是“滚动更新”。
- 依赖
health check机制- 保证服务的连续性
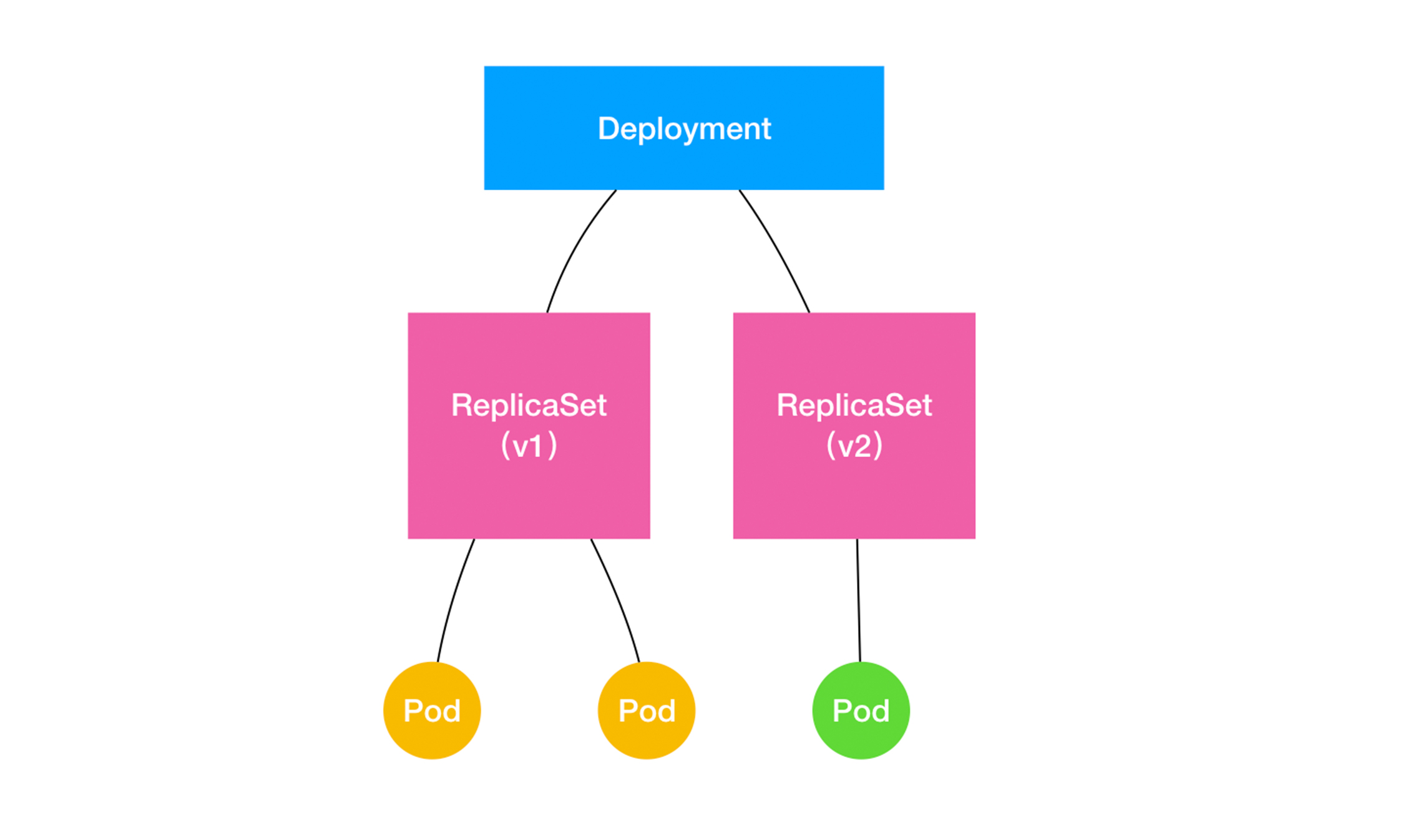
Deployment 实际上是一个两层控制器。首先,它通过 ReplicaSet 的个数来描述应用的版本;然后,它再通过 ReplicaSet 的属性(比如 replicas 的值),来保证 Pod 的副本数量。
深入理解StatefulSet
- 拓扑状态:应用间不完全对等,需要谁先启动,谁后启动,必须按照某些顺序来启动。(在
Pod删除和再创建中保持稳定) - 存储状态:多个实例绑定了不同的存储数据,一个数据库应用的多个存储实例
拓扑状态
StatefulSet 核心功能:通过某种方式纪录这些状态,等POD被重新创建时候,能够为新的POD恢复状态。
Headless Service
Service 是 Kubernetes 项目中用来将一组 Pod 暴露给外界访问的一种机制。比如,一个 Deployment 有 3 个 Pod,那么我就可以定义一个 Service。然后,用户只要能访问到这个 Service,它就能访问到某个具体的 Pod。
- 第一种方式,是以
Service的VIP(Virtual IP,即:虚拟 IP)方式。 - 第二种方式,就是以
Service的DNS方式, 比如 只要我访问“my-svc.my-namespace.svc.cluster.local”这条 DNS 记录,就可以访问到名叫my-svc的Service所代理的某一个Pod。
Service DNS 下两种处理方法
Normal Service。这种情况下,你访问“my-svc.my-namespace.svc.cluster.local”解析到的,正是 my-svc 这个 Service 的 VIP,后面的流程就跟 VIP 方式一致了。Headless Service。这种情况下,你访问“my-svc.my-namespace.svc.cluster.local”解析到的,直接就是 my-svc 代理的某一个 Pod 的 IP 地址。可以看到,这里的区别在于,Headless Service 不需要分配一个 VIP,而是可以直接以 DNS 记录的方式解析出被代理 Pod 的 IP 地址。
Headless Service Yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
StatefulSet Yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
# 多了这个 ServiceName 就是告诉 StatefulSet 控制器,在执行控制循环(Control Loop)的时候,请使用 nginx 这个 Headless Service 来保证 Pod 的“可解析身份”。
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
name: web
,对于“有状态应用”实例的访问,你必须使用 DNS 记录或者 hostname 的方式,而绝不应该直接访问这些 Pod 的 IP 地址。
存储状态
StatefulSet 存储状态的管理机制,主要使用的是一个叫做 Persistent Volume Claim 功能。
要在一个 Pod 里面声明 Volume,只要在 Pod 里加上 spec.volumes 字段,然后就可以在这个字段里面定义一个具体的类型的 Volume。比如 hostPath。
Kubernetes 项目引入了一组叫作 Persistent Volume Claim(PVC)和 Persistent Volume(PV)的 API 对象,大大降低了用户声明和使用持久化 Volume 的门槛。
使用PVC的两步:
- 定义一个
PVC,声明想要的Volume属性
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pv-claim
spec:
accessModes:
- ReadWriteOnce # 挂载方式:可读写,并且只能被挂载在一个节点上,非多个节点共享
resources:
requests:
storage: 1Gi #存储大小
- 在应用
POD中,使用这个PVC
apiVersion: v1
kind: Pod
metadata:
name: pv-pod
spec:
containers:
- name: pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: pv-storage
volumes:
- name: pv-storage
persistentVolumeClaim:
claimName: pv-claim # 指定上面的PVC的名字
从上面来看,这个 Volume 又从何而来呢?(运维人员维护的 PV)
# 这个 PV 对象的 spec.rbd 字段,正是我们前面介绍过的 Ceph RBD Volume 的详细定义。而且,它还声明了这个 PV 的容量是 10 GiB。这样,Kubernetes 就会为我们刚刚创建的 PVC 对象绑定这个 PV
kind: PersistentVolume
apiVersion: v1
metadata:
name: pv-volume
labels:
type: local
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
rbd:
monitors:
# 使用 kubectl get pods -n rook-ceph 查看 rook-ceph-mon- 开头的 POD IP 即可得下面的列表
- '10.16.154.78:6789'
- '10.16.154.82:6789'
- '10.16.154.83:6789'
pool: kube
image: foo
fsType: ext4
readOnly: true
user: admin
keyring: /etc/ceph/keyring
所以 Kubernetes 中的 PVC 和 PV 的设计,类似于 “接口” 和 “实现” 的思想,这种解耦,避免了暴露系统更多的细节,也是职责的分离,更容易定位问题
StatefulSet 的工作原理
StatefulSet控制器直接管理的是PODKubernetes通过Headless Service为这些有编号的POD。在DNS服务器众生成同样带有编号的DNS纪录。只要StatefulSet能够保证这些POD的名字编号不变,类似 “web-0.default.svc.cluster.local” 这样的DNS纪录就不会变,而这条纪录解析出来的POD的IP地址,会随着后端的POD删除和再创建而更新。StatefulSet还为每个POD分配并创建一个同样编号的PVC,这样Kubernetes可以通过Persistent Volume机制为这个PVC绑定对应的PV,保证一个POD都有一个独立的Volume(即使POD被删除,但是对应的PVC和PV保留下来,重新创建POD的时候,还会找回来,数据还存在)
容器化守护进程的意义 DaemonSet
DaemonSet 主要的作用: 在Kubernetes集群里运行一个 Daemon Pod,这个Pod三个特征
- 每个
Kubernetes节点都会运行一个这样的POD - 每个节点上只有一个这样的
Pod实例 - 当有新的节点加入
Kuberntes集群后,该Pod会自动的在新的节点上被创建出来,而当旧节点被删除后, 它上面的 Pod 也会相应地被回收掉。
eg:
- 网络插件的 Agent 组件,必须运行在每个节点上,用来处理容器的网络
- 存储插件 Agent 组件,必须运行在每个节点上,用来挂载远程存储目录,操作容器的 Volume 目录
- 监控组件 以及 日志组件,也是一样,负责节点的监控信息和日志收集
跟其他编排不一样,DaemonSet 开始运行的时机,很多时候比整个 Kubernetes 集群出现的还要早。比如容器网络组件,在所有的 Worker节点状态都是 NotReady。
# fluentd-elasticsearch 镜像POD, 通过 Fluentd 将 Docker 容器日志转发到 ES 内。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: k8s.gcr.io/fluentd-elasticsearch:1.20
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
# 挂载了两个hostPath类型 的 Volume
volumeMounts:
- name: varlog
mountPath: /var/log
# Docker 容器里应用的日志,默认会保存在宿主机的 /var/lib/docker/containers/{{. 容器 ID}}/{{. 容器 ID}}-json.log 文件里,所以这个目录正是 fluentd 的搜集目标
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
DaemonSet Controller,首先从 Etcd 里获取所有的 Node 列表,然后遍历所有的 Node。这时就会去检查这个Node上是不是已经存在携带了 name=fluentd-elasticsearch 的 POD 在运行了
- 没有这个POD,则创建一个新的 POD
- 有这种POD,数量 > 1, 删除多余的
- 正好一个,节点正常
DaemonSet 会自动加上 tolerations字段
apiVersion: v1
kind: Pod
metadata:
name: with-toleration
spec:
# “容忍”所有被标记为 unschedulable“污点”的 Node;“容忍”的效果是允许调度。
tolerations:
- key: node.kubernetes.io/unschedulable
operator: Exists
effect: NoSchedule
在正常情况下,被标记了 unschedulable“污点”的 Node,是不会有任何 Pod 被调度上去的(effect: NoSchedule)。可是,DaemonSet 自动地给被管理的 Pod 加上了这个特殊的 Toleration,就使得这些 Pod 可以忽略这个限制,继而保证每个节点上都会被调度一个 Pod。当然,如果这个节点有故障的话,这个 Pod 可能会启动失败,而 DaemonSet 则会始终尝试下去,直到 Pod 启动成功。
离线业务 Job 与 CronJob
像在线业务诸如应用一类的,抽离了描述离线业务的API对象:Job
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: resouer/ubuntu-bc
command: ["sh", "-c", "echo 'scale=10000; 4*a(1)' | bc -l "]
restartPolicy: Never
backoffLimit: 4
$ kubectl describe jobs/pi
Name: pi
Namespace: default
Selector: controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495
Labels: controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495
job-name=pi
Annotations: <none>
Parallelism: 1
Completions: 1
..
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495
job-name=pi
Containers:
...
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {job-controller } Normal SuccessfulCreate Created pod: pi-rq5rl
这个 Job 对象在创建后,它的 Pod 模板,被自动加上了一个 controller-uid=< 一个随机字符串 > 这样的 Label。而这个 Job 对象本身,则被自动加上了这个 Label 对应的 Selector,从而 保证了 Job 与它所管理的 Pod 之间的匹配关系。而 Job Controller 之所以要使用这种携带了 UID 的 Label,就是为了避免不同 Job 对象所管理的 Pod 发生重合。
如果作业失败了怎么办?
定义了 restartPolicy=Never,那么离线作业失败后 Job Controller 就会不断地尝试创建一个新 Pod 我们就在 Job 对象的 spec.backoffLimit 字段里定义了重试次数为 4(即,backoffLimit=4),而这个字段的默认值是 6。 定义的 restartPolicy=OnFailure,那么离线作业失败后,Job Controller 就不会去尝试创建新的 Pod。但是,它会不断地尝试重启 Pod 里的容器
Job 对象中,并行作业的控制方法
- 1、spec.parallelism,它定义的是一个 Job 在任意时间最多可以启动多少个 Pod 同时运行;
- 2、spec.completions,它定义的是 Job 至少要完成的 Pod 数目,即 Job 的最小完成数。
常用的使用 Job对象的方法
- 外部管理器 + Job模板 (sed)
apiVersion: batch/v1
kind: Job
metadata:
# 带遍历替换
name: process-item-$ITEM
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: jobexample
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: busybox
command: ["sh", "-c", "echo Processing item $ITEM && sleep 5"]
restartPolicy: Never
拥有固定任务数目的并行Job
指定并行度(parallelism),但不设置固定的 completions 的值。
CronJob 对象
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
# cron
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
CronJob 是专门管理 Job 对象的控制其。只不过它的创建和删除Job依据是根据 schedule 字段来定义的。
在 定时任务的时候,可能有任务未执行完毕,就下面的Pod启动
- concurrencyPolicy=Allow,这也是默认情况,这意味着这些 Job 可以同时存在;
- concurrencyPolicy=Forbid,这意味着不会创建新的 Pod,该创建周期被跳过;
- concurrencyPolicy=Replace,这意味着新产生的 Job 会替换旧的、没有执行完的 Job。
# startingDeadlineSeconds=200,意味着在过去 200 s 里,如果 miss 的数目达到了 100 次,那么这个 Job 就不会被创建执行了
spec.startingDeadlineSeconds 时间窗口