Golang的池化设计
Why Pool?
先埋坑: Go 有没有池化的必要? 为什么要池化?
Go 自从出生以来都被我们冠以"高并发"的Tag, 回头细想和深究一下,你会发现其实都是由 goroutine 实现的 ,
我们都知道 与 Thread 相比, 创建 Goroutine 的代价非常小。从程序表现上,也像极了Thread, 每个 Program 至少包含一个 Goroutine(至少一个**Main Goroutine**)
所有的其他 Goroutines 都依附于 Main Goroutine(如果 Main Goroutine Terminated, 其他 Goroutines 也会 Terminated), Goroutine 总是工作在后台。
多线程``多进程是为了提高系统的并发能力,当前系统下,这边就需要系统调度,一个线程可以拆分为 "用户态"线程 和 "内核态"线程,这两者需要进行绑定,我们一般称 内核态线程 为线程,用户态线程为协程
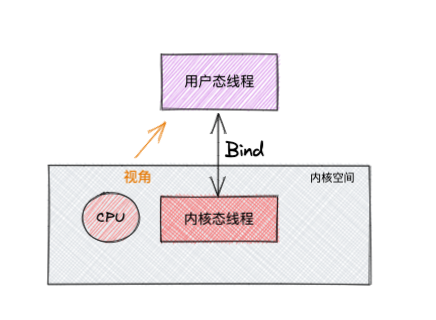
从上面可以看出 协程 和 线程 有映射关系,这样就来了 M:N 关系(为什么不是 1:1, N:1 ? )
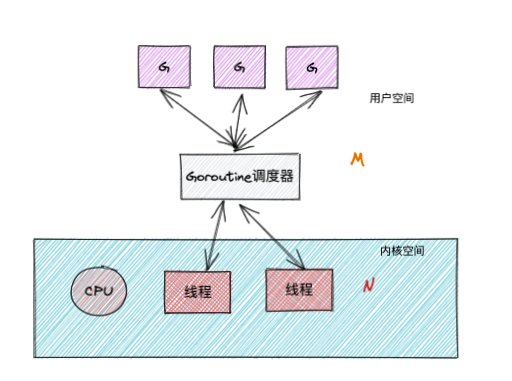
Goroutine 优点:
- 相比
Thread代价更小 Goroutine其在stack的大小可以根据程序要求进行变化,但是Thread是固定的Goroutine使用Channel进行通信,Channel用于Goroutines访问共享内存的时候防止竞争的。- 从程序上一个线程可能拥有许多的
Goroutines关联,如果这些关联的 有一个Goroutine去阻塞了线程,那么剩余的Goroutine将分配给其他的OS Thread,且这种切换操作是对开发者屏蔽的。
Goroutine 调度器
回头看将 Goroutine 和 协程 有区别的。调度
好了,那么 Goroutine是如何去调度的, 这个需要了解 Golang协程的 G-P-M 调度模型?
官方: https://docs.google.com/document/d/1ETuA2IOmnaQ4j81AtTGT40Y4_Jr6_IDASEKg0t0dBR8/edit#
Goroutine的调度模型示意图:
- 废弃的
Goroutine调度器 Goroutine调度器
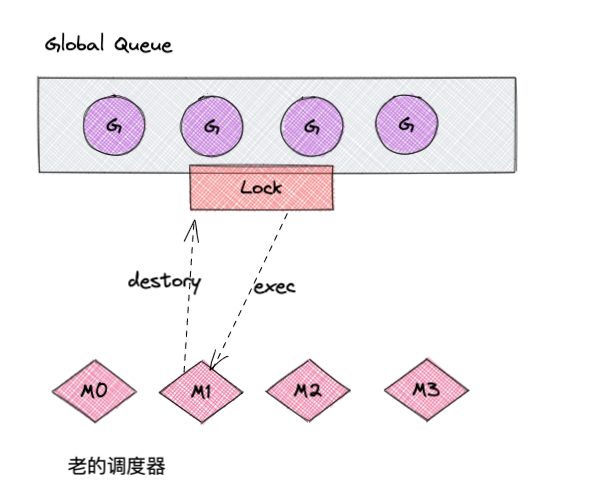
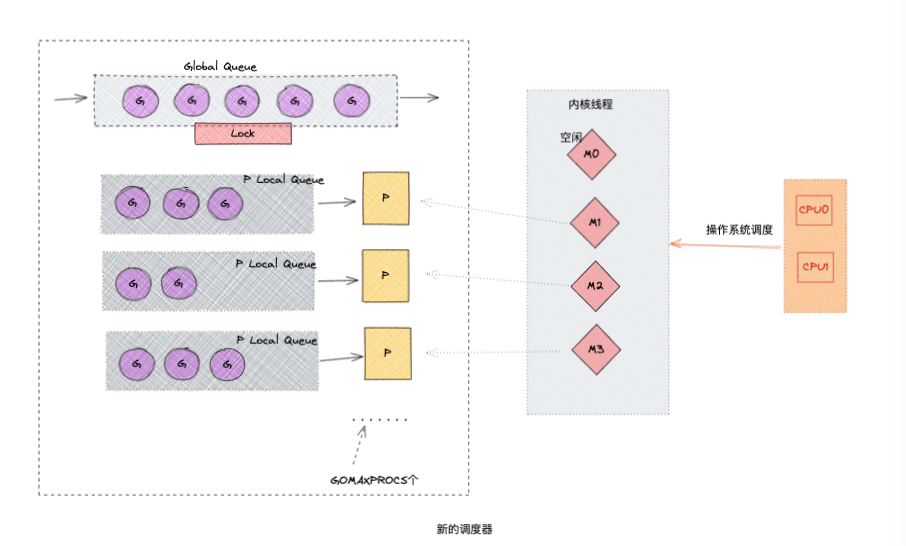
从上图中可以看出
Goroutine调度器将可以运行的goroutine分配到工作线程,
M: 代表 Thread
P: 代表 Processor
G: 代表 Goroutine
- 废弃的调度方式
M要执行、返还G都必须访问全局的G队列(这个队列是加锁的,这就导致了访问全局G队列是通过互斥锁保证的。)- 创建、销毁、调度
G都需要每个M获取锁,形成了竞争 - 系统调度(
CPU与M之间的切换),导致频繁的线程阻塞、取消阻塞操作,增加开销
- 新的调度方式
Global Queue存放等待运行的GP Local Queue同上,存放等待运行的G,不能超过256个, 在新建G的时候优先加入到P Local Queue,如果Queue已满,就移动Local Queue中的一半G到Global Queue。P, 所有的P都在程序启动的时候创建,并保存在数组中,最多GOMAXPROCS个M, 线程想运行任务必须获取到P,P才是G和M的离合器,从P Local Queue获取G,P Local Queue为空时候,M会尝试从Global Queue获取一批G放到P Local Queue,或者从其他的P Local Queue窃取一半的G放到自己的P Local Queue。M执行运行G,G执行后,M会P获取下一个G,不断的重复执行。
P.S.:
关于
P和M的关系
P
P的数量($GOMAXPROCS或runtime的GOMAXPROCS())决定,在程序执行的任意时刻都只有$GOMAXPROCS在同时执行- 在确定
P的最大数量n后,运行时系统会根据这个数量创建n个P
M
M的数量go语言限制, 设置M的最大数量,当然这个默认值基本可以忽略(10000, 内核很难支持这么多)runtime/debug中的SetMaxThreads函数- 一个
M阻塞了,会创建新的M- 没有足够的
M来关联P并运行其中可运行的G(M都阻塞了、P还有很多就绪等待的,就会寻找空闲的M,如果没有空闲的M,就会选择创建新的M)
综上看 Goroutine 的调度器设计的考虑:
复用线程:避免频繁的创建、销毁线程。对线程复用work stealing机制: 当P Local Queue无可运行的G时候,尝试从其他线程绑定的的P的P Local Queue获取Ghand off机制: 当线程因为G进行系统调用阻塞时候,线程释放绑定的P,把P转移给其他空闲的线程执行
并行:GOMAXPROCS设置P的数量,最多有$GOMAXPROCS个线程分布在多个CPU进行同时运行,GOMAXPROCS也限制了并发,假如GOMAXPROCS<CPU核数,则最多用GOMAXPROCS个CPU核进行并行Global Queue,弱化了Global Queue的设计,当M执行work stealing从其他的P偷不到G时候,它可以从Global Queue获取G
Go func 的调度流程
直接展示流程图
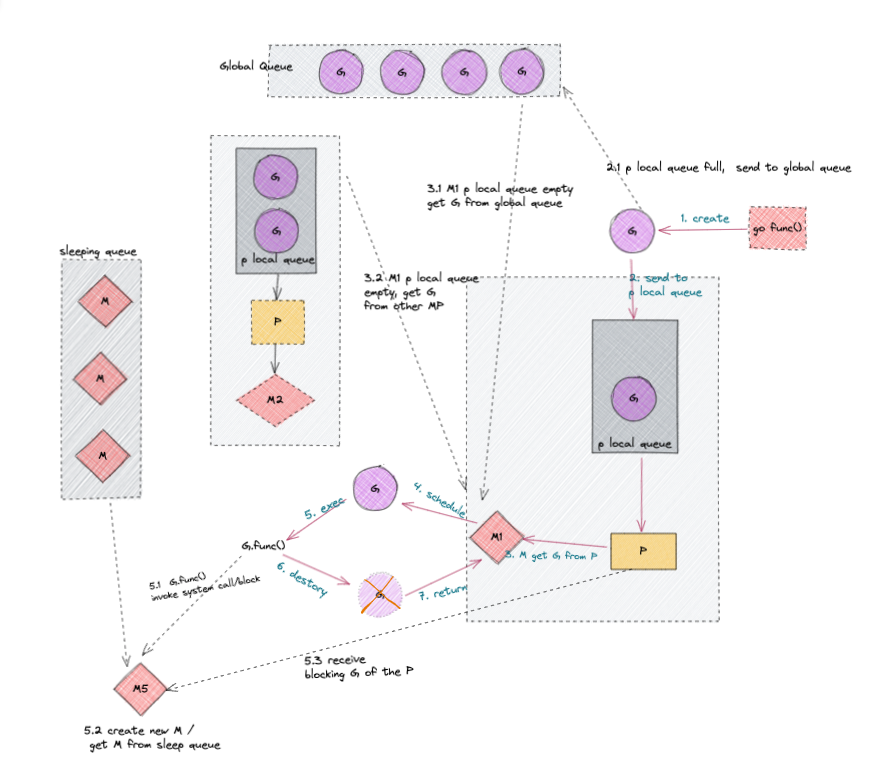
go func开启一个goroutine- 两种类型的存储
G的queue, 一种P Local Queue,一种Global Queue。新创建的G会优先保存在P的Local queue,如果P Local Queue满了就会保存到Global Queue。 G运行的载体是M(即线程), 且一个M必须持有一个P,M:P=1:1。M会从P Local Queue获取一个可执行状态的G来执行,如果P Local Queue为空,会从Global Queue获取一批可执行的G或者从其他MP组合获取一半的可执行的G来存储到其所关联的Local Queue来执行。M循环的从P中获取G来执行的- 当
M执行某个G时候如果发生syscall或者其他block操作,M阻塞了,如果当前还有一下其他的G在执行,runtime会把这个线程M从P中detach,创建一个新的M(如果空闲从空闲中获取)来服务这个P。 M调用结束,G尝试获取一个空闲的P执行,并放入到 这个P Local Queue,如果获取不到P, 那么线程M进入 休眠状态,加入到空闲线程中,这个G会被存放到Global Queue中。
总结论调
上面了解 Golang 实现协程机制 与 goroutine 的调度机制,那么 Golang 开发需要做池化么?
要论述次问题,需要做的是结合真实应用场景。
- 假设是一个小型的项目,且机器的配置完全撑的住预知的并发量,对
goroutine做池化就没必要了。当然不排除后续需要的进行的优化。 - 但是针对一个现有的互联网、物联网等商业环境上,绝大部分生产系统在个人认为还是都是需要做池化动作的。
需求场景描述: 当一个百万主播开启直播,在该网红要直播的时候,要对其大量的订阅粉丝进行推送直播开启通知的。
Memory上: 直接依赖goroutine的设计,将粉丝都处理出来,依赖非同步的批量处理来并行处理(开启每个goroutine进行200个的订阅粉丝通知操作)。
假设一个机器使用2GB的Memory,每个goroutine是2KB,则理论上能开启100w个初始化状态的goroutine, 但实际上每个goroutine的大小跟随开启的数目而增长上去。
在考虑到系统预留等,和其他情况取1/10的作为稳定状态,同样的配置在一台机器上只能跑10w个goroutine,
那么在之前的需求,一个百万粉丝的主播开播,这样光完成一个主播就需要在一瞬间启动1w个goroutine,那么在高峰热门时段,一台机器最多也只支撑了10个主播开播。且高频率开启销毁 goroutine 造成CPU``100%。
总结上述操作问题:
- 需要一个限制
goroutine最多数量 - 需要缓存临时存储,让有限的
goroutine能缓冲的消化掉 goroutine能重用,减少产生的代价
综合看完,这就是一个池化的设计实现方式。
- 第一点管理
goroutine, 使用一个goroutinearray 来管理 - 缓存设计,设计
queue, goroutine 的协作通信通过 channel, channel(unbuffered channel 、buffered channel) 使用这个作为queue,预设置0(走unbuffered channel),其他的可以设置queue的长度,走buffered channel机制, goroutine能重用,开始创建的时候,预设置一个初始的大小,并且设置一个最大的pool最大限制。 在初始的时候只创建核心的,然后随着任务的增长和需求赠度,慢慢的增长数量直至达到pool的限制。策略上优先任务放入到queue,queue满了后再新建goroutine去执行并加入到pool, 这样的设计,在突发情况能应接。当系统空闲,能将过多的goroutine进行回收回复到初始化大小。
当然也有其他的优秀的开源池化组件,当前
Ref: