重学Redis
redis
redis 是BSD许可的开源内存数据中间件,可以用作 数据库、缓存、消息Broker、流引擎。
redis 数据类型
data structures:
stringshasheslistssetssorted sets [range queries]bitmapshyperloglogsgeospatial indexesstreams
redis key 的推荐规则
keys rule:
- 不要设置过长的
KEY - 过短的
KEY也不建议 - 适中,并且能达意的,考虑用分隔符
- 最大的
KEY SIZE:512MB.
String
Redis 存储字符序列、可以是 文本、序列话对象、二进制数组。支持 incr 操作。
SETSETNXGETMEGT
大部分字符串操作都是 O(1), 但是 SUBSTR、GETRANGE、SETRANGE 可能是 O(n)
Redis String 是才赢得 SDS 实现的(Simple dynamic string)
在执行 set hello helloval后底层是
- 那么键的字符串对象,底层创建保存 ‘hello’ 的
SDS - 那么值也是字符串对象,底层创建保存字符串的 ‘helloval’ 的
SDS
SDS 的结构体
struct sdshdr {
char buf[]; //字节数组,用于保存字符串
int len; //记录buf数组中已经使用字节的数量
int free; //记录buf数组内未使用的字节的数量
}
- 对比
C,有专门的字段记录buf数组的字符串长度和空闲 时间复杂度O(1) - 对比
C,记录字符串了长度,在进行分配的时候,或修改的时候,杜绝了缓冲区溢出的可能性,在SDS API对SDS进行修改的时候,会先检查空间是否满足修改的需求,不满足的话,会先拓展至执行所需要的大小,再执行修改操作。 - 减少字符串修改带来的内存重分配操作, 通过
free参数记录未使用的空间,这样实现了空间预分配和惰性空间释放策略 - 二进制安全。因为有
len属性,不需要判断字符串确认是否是末尾。可以存储任意结构的二进制数据 - 兼容部分C函数
Lists
通过链表实现的、即使有数百万元素,在列表头部或尾部添加新元素的操作都是O(1): LPUSH 同时向10个元素和100万个元素添加头部元素的速度是相同的。
最大的长度 2^32 - 1
实现 堆栈 或 队列
后端分布式系统构建队列使用
LPUSHLPOPLLENLMOVELTRIM
例子
- 记录用户发布社交网络的最新更新(
LPUSH、LRANGE) - 进程间通讯,生产消费模式,生产者将元素推进入列表中(
LPUSH),消费者消费这些元素(RPOP)
访问其头部或尾部的列表操作是 O(1),但是操作列表中元素通常是 O(n), LINDEX、LINSERT、LSET
Sets
唯一字符串成员的无序集合。
最大的长度 2^32 - 1
SADDSREMSISMEMBERSINTERSCARD
SADD、SREN、SISMEMBER 是 O(1)。 SMEMBERS 在大型集合时候是 O(n), 替换方案 SSCAN
Sorted Sets
通过相关分数排序的唯一字符串成员集合, 当分数相同的时候,这些字符串按字典顺序排列
排行榜,排序最高分的有序列表
速率限制器,通过滑动窗口速率限制器防止更多的API请求
ZADDZRANGEZRANKZREVRANK
大多数集合操作都是 O(log(n)), n 是成员数
Hashes
通过 键值对 的集合,
最多存储散列的是 2^32 - 1, 但是往往 值受限于 VM 总内存限制
HSETHGETHMGETHINCRBY
大部分 O(1) , HKEYS,HVALS、HGETALL 是 O(n), n是键值对的数量
Hash 是一个很常见的数据结构、Redis 的实现是一个比较经典的方案。 其采用了链式哈希,在不扩容哈希表的前提下,将相同哈希值的数据链起来。 在针对rehash 的上,设计了渐进式rehash设计,缓解了rehash操作带来的额外开销。
链式哈希
哈希是将不定长的变成定点长的操作,- 一个最简单的哈希是一个数组,数组的每个元素等于一个
哈希桶 - 会存在多个
key哈希完后是同一个值,这个就是哈希冲突。那么解决哈希冲突最简单的方式就是,哈希桶下挂载链表,链表内存储的是值
往往我们在新开启的哈希桶的时候,因为无法预知数据大小,所以不会一下子开辟很大哈希表。链式哈希带来了问题是
hash碰撞:带来了在单个Hash桶上退化为链表,损失了高性能( 数组O(1)的时间复杂度 变成了 链表的O(N)的复杂度 )无序性:HashMap的Hash桶数组的顺序与put操作的先后顺序无关
无序性还好,但是 hash碰撞带来的问题是导致Hash桶的扩容,如果大批量的数据,触发负载因子后触发hash桶的扩容。如果不设计一套扩容方案,会导致要数据分配完毕才进行其他操作,会丧失 redis 的高性能, 所以 Redis 设计了一套 渐进式Rehash
渐进式Rehash
Redis 默认使用了 两个 全局Hash表,先使用的是 Hash表A,此时另外的 Hash表B 并未被分配空间,随着 Hash表A 的数据增多,Hash碰撞越来越多拉低了 redis 的性能,开启 rehash操作:
- 给
Hash表B申请较大的空间,入Hash表A的哈希桶数组容量的2倍 - 将
Hash表A的元素重新计算Hash和取模运算,映射到Hash表B中 - 清理
Hash表A
具体过程是
- 从
Hash桶数组 的第一个 节点开始,每次处理客户端一个请求,想Hash表B中Copy一组Hash桶的数据。直到所有的节点数据COPY完成
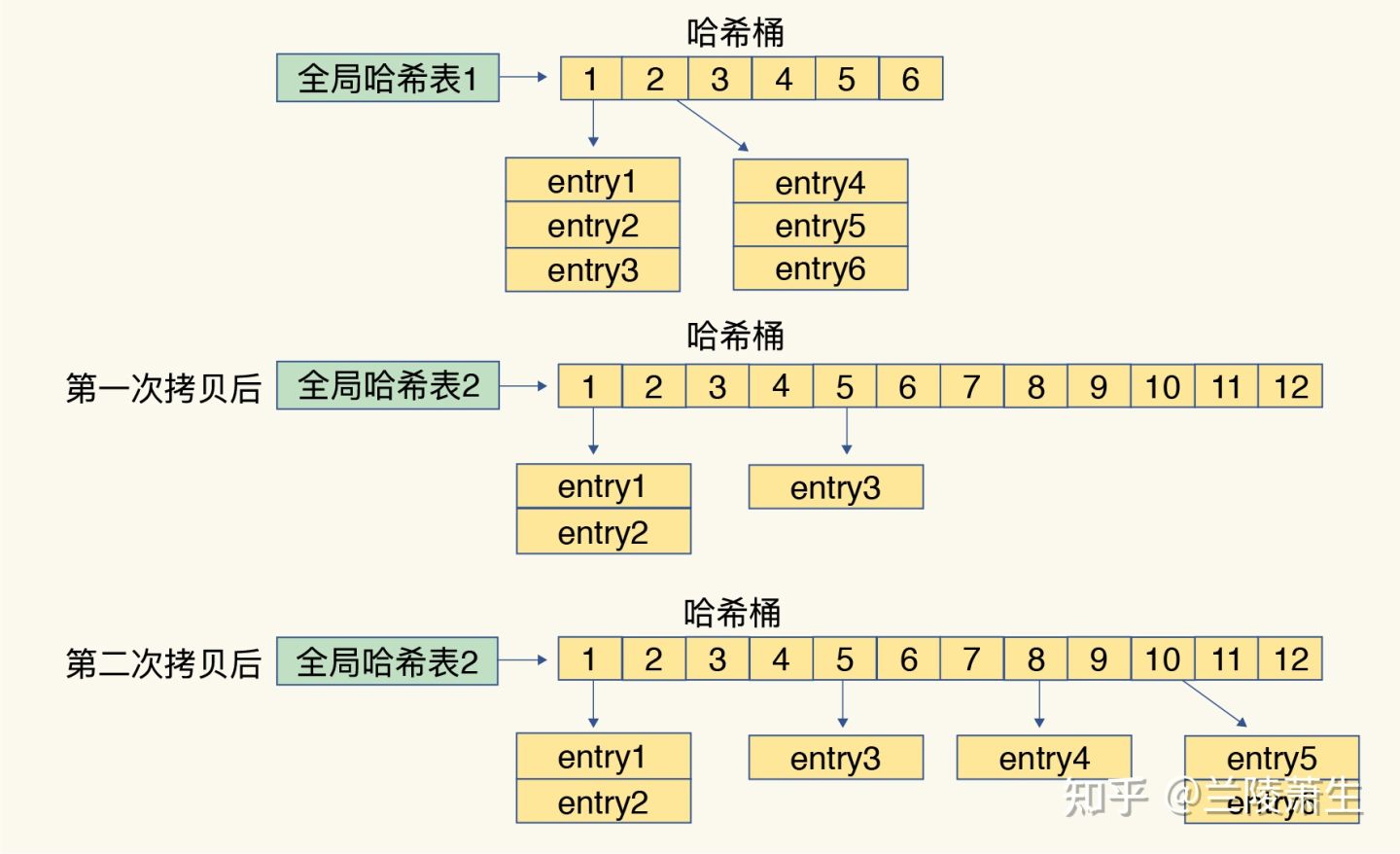
rehash 和 hashmap 的扩容区别
- rehash 扩容 两个 hash表,hash表B 的扩容是 Hash表A 的 2倍,扩容过程中新加入的元素直接添加到 hash表B
- hashmap 的 resize,
Streams
Stream 是一种数据结构、作用类似于 附加日志,可以使用 Stream 实时记录 和 同步事件。
Redis 为 每个Stream 条目生成一个唯一的ID,可以使用这个ID进行检索和关联条目
事件溯源
设备监控
通知
XADD向Stream添加条目XREAD读取或者多个条目,从给定位置开始XRANGE返回两个ID之间的条目范围XLEN返回Stream的长度
向 Stream 添加是 O(1), 访问任何单个条目都是 O(n), Nx是 ID 的长度
Geospatial
地理空间坐标用来搜寻给定半径 或 边界范围 的附近点的。
GEOADD将位置添加到给定的地理空间索引,经度位于纬度之前GEOSEARCH返回具有给定半径或边界框的位置
HyperLogLog
HyperLogLog 是一种估计集合基数的数据结构、是一种概率数据结构。以准确性换取了空间利用率。
HyperLogLog 可以估计具有多达 2^64 个成员的基数
PFADD将元素添加到HyperLogLogPFCOUNT返回集合中元素的估计值PFMERGE将两个或者多个HyperLogLog合并成一个
PFADD、PFCOUNT 都是恒定时间和空间完成的 ,合并 HLL 是 O(n), n 是草图的数量
BitMaps
bitmaps 是字符串类型数据的扩展,可以将字符串视为响亮,可以对一个或者多个字符串执行按位运算。
对于 集合的成员对应与
0-N的请客,有效的集合对象权限、每个位代表一个特定权限。
SETBIT将提供偏移量设置为0或1GETBIT返回给定偏移量的位值BITOP允许对一个或多个字符串执行按位运算
SETBIT 、GETBIT 都是 O(1), BITOP 是 O(n), n 是比较中最长字符串的长度
Bitfields
Client-side caching
客户边缘缓存技术是一种提高性能的服务技术。顾名思义,是借助客户端的可用内存去存储部分从数据库端获取到数据子集。
特点
- 数据可以以非常小的延迟可用
- 减少数据库的查询,提高性能
Key eviction
maxmemory 配置的是为数据集使用制定数量的内存,设置为 0 ,没有内存限制(64位)【32位的是默认的3GB】
noeviction:达到内存限制,怒不保存新的allkeys-lru:保留最近使用的,删除最近最少使用的allkeys-lfu:保存经常使用的,删除最少使用的 LFUvolatile-lru:删除 expire 为 true,最近最少使用的volatile-lfu:删除 expire 为 true 的最不常用的allkeys-random:随机删除volatile-random:随机删除 expire 为 truevolatile-ttl: 删除 expire 字段为 true 且 最短剩余生存时间(TTL)
淘汰驱逐的过程:
- 客户端运行新命令、服务端添加新的数据。
Redis检查内存使用情况、如果大于maxmemory限制, 它回根据策略驱逐- 执行命令,添加数据
High availability Sentinel
Sentinel 是在不实用 Cluster 提高可用性的。包含的功能有
- 监控:
sentinel节点会定期检测redis数据节点(主从)、其余Sentinel节点是否可达 - 通知:
sentinel节点会将故障转移的结构通知给应用方 - 自动故障转移: 主节点不可用,从节点晋升为主节点并维续后续正巧的主从关系
- 配置提供者:
Redis Sentinel,客户端在初始化的时候连接的是Sentinel节点的集合,从中获取主节点的信息
keyspace notifications
Keyspace 通知允许客户端订阅 Pub/Sub 频道,以便接收以某种方式影响 Redis 数据集的事件。
- All the commands affecting a given key.
- All the keys receiving an LPUSH operation.
- All the keys expiring in the database 0.
键空间通知是通过为 影响数据空间的每个操作发送两种不同类型的事件实现的。
Persistence
redis 如何将数据写入磁盘的,append-only files、snapshots!
持久性是将数据写入持久存储设备。
- RDB(Redis Database) 以指定时间间隔执行数据集的时间点快照
- AOF(Append Only File): AOF 持久化记录服务器接受的每个写操作,在服务器启动的时候,再次进行回放,重建原始数据集。 指令的写入是与Redis协议相同,以追加的方式记录。
- No persistence
- RDB + AOF 可以在同一个实例中结合使用
AOF+RDB, 这种情况下,数据最完整。
RDB 优势
RDB是redis数据非常紧凑的单元时间点表示的,RDB文件非常适合备份, 可以在最近24小时内每小时归档一次RDB文件,并在30天每天保存一份RDB文件。可以多个版本的RDB非常适合灾难性恢复(他其实就是一个加密的压缩文件)RDB最大化的提高性能,RDB在大数据集的情况下重启比AOF快- 在同步副本上,
RDB在重启 和 故障转移的情况下支持 部分同步
RDB 缺点
- 在要求对数据丢失的可能性最低的情况下,
RDB并不好。因为是定期备份,在这个单位时间内停止工作的会,导致丢失最新的数据 RDB需要经常fork(),在子进程持久化数据存盘的时候。Fork操作可能很耗时,同时大数据集的时候会影响CPU性能。AOF也需要fork但是频率很低。
AOF 优势
- 更多的
fsync策略: 从不fsync、每秒fsync, 每次查询时fsync,fsync是后台线程执行, AOF日志是 追加日志,因此没有寻址问题,也不会在断电的时候出现损坏问题,即使某个原因日志写一半命令结束,也可以使用redis-check-aof工具恢复它AOF变得很大的时候,redis可以在后台自动重写AOF。重写是完全安全的,因为当redis继续追加旧文件的时候,会使用创建当前的数据集做少的操作集重新生成一个全新的文件,一旦文件准备完毕,redis就会切换两者并追加哦到新的文件AOF操作日志,是易于理解和解析的。可以轻松的导出AOF文件
AOF 缺点
AOF文件通常比相同的数据集大小的RDB文件大- 根据确定的
fsync策略,AOF可能比RDB慢, redis < 7.0在重写期间对数据库的写入,AOF会使用大量的内存(当前的写入被缓冲在内存,到最后写入)redis < 7.0重写期间到达的写入命令会写入磁盘两次redis < 7.0Redis可以在重写结束时候,冻结写入并将这些写入命令同步到新的AOF文件
Pub/Sub
7.0 之后 引入了 Sharded Pub/Sub, 在之前的版本,对于集群的 channel 不被当成数据处理,导致了就不回参与 hash计算,无法按 slot 分发到节点,所以在 7.0之前 集群模式下的 redis 对于 pub/sub 是采用广播的方式,这会带来广播风暴的问题。
假设集群 100 个节点,用户在对 节点1 的某个 channel 进行 publish 发布消息,该节点需要将消息广播给其他 99 个节点,如果有的节点只有少量订阅,且绝大部分消息对其来说是无效的。这对 CPU 和 网络都是开销。
而 Shared pub/sub 就是解决该问题, 会把 channel 按 分片来进行分发,一个分片节点只负责处理属于自己的 channel 而不进行广播
Replication
replication 是 提供 支持高可用性 和 故障转移的根本。
Master和Replica连接良好时候,Master通过发送命令数据集来对副本进行更新,包含了写入、过期、驱逐、更改等任何操作- 当
Master和Replica连接中端时候,由于 网络问题 或者Master和Replica之间检测超时,Replica会重连、在重连成功后获取断开连接期间错过的命令流。 - 当
Replica确实无法重新同步是,Replica将采用备用方案,请求全部重新同步,这边Master需要创建一个所有数据的快照,将其发送到Replica,并随着 数据的变化继续发送命令流
Redis 默认采用的 异步复制。异步复制的特点:
Redis是异步复制,异步复制的是Master acknowledges的数据- 一个
Master允许多个Replicas Replica能接受其他Replica的连接,除了多个Replica连接 同一个Master外,Replica还可以类似级联的结构连接到其他副本Redis复制在Master是非阻塞的,当一个或多个Replica执行 同步 或 部分重新同步的时候,主Master将继续处理查询。Replica在 复制的绝大部分都是非阻塞的,- 复制 可以用于拓展
redis的扩展性,也可以用于 复制只读查询的副本 - 复制 可以 避免 让
Master将完整的数据写入磁盘
redis 复制
复制的流程:
Master实例都有一个复制ID(一串大的随机字符串),标记数据集的,还有一个offset(它随着要发送给副本的数据流的字节增加),即使没有实际联结的副本, offset 也会增加。 也技术说Replocation ID, Offset是标记着数据集合的准确版本。- 当 副本实例 连接
Master时候,使用PYSNC命令发送 他们保存的旧主服务器复制ID和 目前他们自己处理的offset。 这样master可以只发送所需要的增量部分 - 如果
主Master的缓冲区没有足够的数据堆积、或者副本饮用的不是已知的复制ID的 历史记录,则会触发完全同步。这样副本集合将会获得完整的数据副本。
完全同步的工作模式:
Master后台开启生成RDB文件,并同时缓冲客户端接受的新的写命令- 后台保存完成后,
Master将RDB文件传输到replica,replica将其保存在磁盘上,然后加载到内存中。 - 后续
Master将所有缓冲的命令 发送到replica,Replica执行这个命令流完成。
复制ID
如果两个实例具有相同的 复制ID 和 复制偏移量(offset), 则它们具有完全相同的数据。但是实际上 实例 上有两个 复制ID : 主ID 辅助ID
Redis 实例为什么会有两个 复制ID,因为 副本 升级为 Master。 故障转移后, 升级的副本仍需要记住它过去的 复制ID,因为这样的 复制ID 是以前的主副本,当其他副本与新的 master 同步时候,他们将尝试使用 旧的Master 复制ID 执行部分重新同步。
当副本升级为 Master 的时候,将把其 辅助ID 设置成 主ID,并记录 发生ID切换的偏移量 是多少。然后,生成一个新的随机 复制ID,用于记录新的开始 。